Parallelism in ML Training
Post Metadata
Modern ML training requires splitting work across clusters of GPUs to process data faster and fit model state into GPU memory. In ML systems, “parallelism” can mean several different things. Data and model parallelism distribute work across devices. Getting good performance also depends on intra-device parallelism: overlapping compute and communication operators on each individual GPU. This post gives an overview of both kinds of parallelism, then describes my work on abstractions for tuning inter- and intra-device parallelism strategies. This work is currently under submission to NSDI.
Inter-Device Parallelism
Inter-device parallelism distributes a training step across GPUs. Different strategies split different parts of the computation, so they introduce different communication patterns.
Data parallelism (DP) splits the input batch across GPUs. Each GPU has a copy of the model, computes gradients for its local data, then runs a collective communication operation to synchronize gradients after the backward pass.
Tensor parallelism (TP) splits a single tensor operation across multiple GPUs, also known as sharding. For example, a matrix multiplication can be split by rows or columns so that each GPU computes one shard of the output. This saves memory and spreads compute across GPUs, but it puts collective communication on the critical path because later tensor operations need the sharded results to be reassembled.
Expert parallelism (EP) is a type of sharding common in mixture-of-experts (MoE) models. A mixture-of-experts layer routes each input token to a small subset of specialized submodules called experts, so the model can have many parameters without activating all of them for every token. Expert parallelism shards experts across GPUs and uses collective communication to route tokens to the GPUs that own their selected experts.
Pipeline parallelism (PP) partitions model layers into stages. Point-to-point send/receive communications propagate activations forward through the pipeline during the forward pass and propagate gradients backward through the pipeline during the backward pass. To improve GPU utilization, pipeline-parallel strategies split a batch into smaller microbatches: the pipeline “schedule” describes how those microbatches flow through pipeline stages over time.
In practice, systems compose several of these strategies according to the model’s architecture. The figure below depicts a mixture-of-experts model with pipeline parallelism across layers and data/expert parallelism within layers. Data parallelism replicates the attention computation and expert parallelism shards the expert computation.
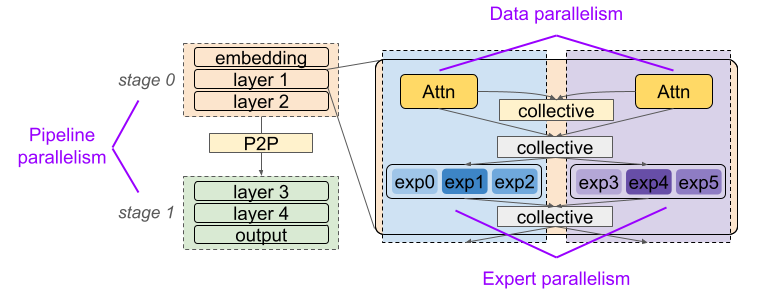
Composing inter-device strategies creates complex communication patterns and high communication overhead. For example, DeepSeek-V3 reports that expert parallelism alone produced an approximately 1:1 computation-to-communication ratio. Maximizing training throughput requires carefully scheduling tensor operators on each GPU to hide communication latency. This is where intra-device parallelism comes in.
Intra-Device Parallelism
The inter-device parallelism strategy determines the necessary communication for a training step. The intra-device parallelism strategy determines how each GPU’s local tensor operators are scheduled. The key is to hide communication latency by overlapping communication with compute while avoiding contention on GPU resources.
Parallelizing work across a GPU’s processors is commonly expressed through GPU streams. A stream is a work queue for launching kernels on a GPU. Operations in the same stream execute in order, while operations in different streams may run concurrently unless constrained by synchronization between streams.
Concurrent GPU work can contend for processors, memory, or network bandwidth. This matters when multiple inter-device parallelism strategies introduce different collective communication operations on the same GPU.
Expert parallelism uses two all-to-all communications (A2A) inside an MoE layer to redistribute token activations to the GPUs that own the selected experts and to send the expert outputs back.
Because expert computation depends on the routed tokens, A2A is on the critical path of the layer.
Data parallelism uses all-reduce communication (AR) after backward computation to average the gradients of replicated model state so all model replicas apply the same update.
Unlike A2A, gradient synchronization is not on the critical path: once a model component’s backward pass has produced its gradients, AR can be scheduled anytime before the optimizer update, creating more opportunities to overlap it with downstream computation.
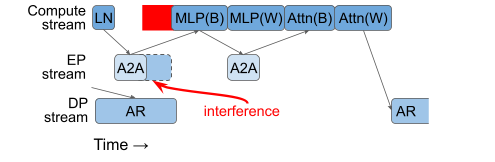
A natural strategy is to put A2A and AR on separate streams so they can run concurrently.
The first figure shows the problem with this choice: the collectives can interfere on the network.
We measured that expert-parallel A2A can be up to 1.42x slower due to interference with data-parallel AR for the Qwen 9B MoE model.
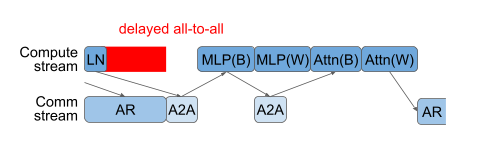
Another strategy is to put A2A and AR on the same stream.
This avoids network interference by serializing the collectives, but now a gradient AR can delay a critical-path expert A2A.
Neither choice is universally best. The right schedule depends on the model architecture, communication sizes, and surrounding pipeline schedule. In practice, general-purpose frameworks like Megatron-LM, DeepSpeed, and TorchTitan don’t expose control over intra-device scheduling. Instead, they opt for eagerly dispatching communication operators for different parallelism dimensions on separate streams, leading to interference that is hard to avoid without invasive runtime changes.
On the other hand, high-performance systems like DeepSeek-V3 invest a lot of effort into hand-writing a custom runtime that tightly couples the inter- and intra-device parallelism strategy to one workload. These kinds of systems offer high performance, but their parallelism strategies are hard to adapt when the model architecture or GPU cluster topology changes.
I’m interested in exposing useful scheduling knobs for tuning the inter- and intra-device parallelism strategy in a general-purpose framework. Domain experts or future automated methods can use such a system to explore the tradeoffs of different strategies without building and building and re-building a custom training system.
Parallelism abstractions
I built a system called Piper that decouples the execution strategy from the model implementation and distributed runtime. The user provides an annotated PyTorch model and a schedule. Piper compiles those inputs into a global execution plan and passes it to the runtime. This post focuses on the user interface.
The first part of the interface are annotations.
Annotations identify schedulable regions of the model.
The following example annotates a mixture-of-experts model, like the one in the first diagram.
The PP annotations identify pipeline stages, while the EP annotation identifies expert computation inside an expert layer.
PP = "pp_tag"
EP = "ep_tag"
class TransformerModel:
def forward(self, x):
with sys.annotate(PP, 0):
h = self.embeddings(x)
h = self.layer1(h)
with sys.annotate(PP, 1):
h = self.layer2(h)
h = self.layer3(h)
h = self.output(h)
return h
class ExpertLayer:
def forward(self, x):
x = self.router(x)
with sys.annotate(EP):
x = self.experts(x)
return x
The annotations give names to semantically meaningful regions of model state and compute so that the schedule can refer to them later.
For example, (PP=0) refers to the first pipeline stage, (EP=*) refers to expert components, and (EP=-) refers to non-expert components (everything outside the EP annotation scope).
The second part of the API is a program of scheduling directives which describe the inter- and intra-device parallelism strategy by referring to annotated model components. Filters apply directives to specific parts of the model.
logical_stream = sys.stream()
Replicate([(PP=0),(EP=-)], devices=[0, 1], stream=logical_stream)
Shard([(PP=0),(EP=*)], devices=[0, 1], stream=logical_stream)
The schedule snippet applies 2-way data parallelism (replication) to non-expert components of pipeline stage 0 and 2-way expert parallelism (sharding) to expert components of pipeline stage 0. Piper infers communication for each directive:
Replicateadds collective communication after the backward pass of matched components to synchronize replicated model state,Shardadds collective communication before and after matched components in the forward and backward pass for token routing.
The stream arguments identify which logical GPU stream the associated communication should run on.
The snippet places both data- and expert-parallel collective communication on the same logical stream, avoiding interference (as shown in the second diagram) at the risk of delaying critical-path expert communication (as shown in the third diagram).
Additional scheduling knobs for mitigating this risk are not described here.
The full directive set also includes Place, Split, and Order which encode pipeline-parallel strategies.
Together, these directives can express common pipeline schedules like 1F1B and its interleaved variant as well as more complex schedules such as DualPipe, which hides expert-parallel communication by overlapping pipeline-parallel microbatches within a GPU.
Current SoTA training frameworks either do not support intra-device microbatch overlapping (Megatron-LM, DeepSpeed) or have adopted support with limited options for performance tuning (TorchTitan).
Conclusion
Parallelism in ML training is not one-size-fits-all. Inter-device strategies decide what gets sharded or replicated across GPUs while intra-device strategies decide how the resulting compute and communication share each GPU. Achieving SoTA training throughput on modern workloads requires carefully tuning both.
Piper is my attempt to make those choices explicit via a small scheduling language over annotated PyTorch models. The long-term goal is to make distributed training systems easier to extend: not just for existing high-performance strategies like DualPipe, but also for future automated exploration over a rich space of execution strategies for emerging model architectures. An open-source release of Piper is coming soon.