Autoformalizing Double Rounding
Post Metadata
This blog post is about a paper under submission at OOPSLA 2026. If you are still reviewing for OOPSLA 2026, please stop reading now!
In March, I submitted a paper on rounding to OOPSLA 2026. This paper described an abstraction of common number formats— sets of representable fixed- and floating-point numbers— along with a number of theorems about rounding, the mapping of real numbers to representable values in a number format. Each theorem came with a pen-and-paper proof.
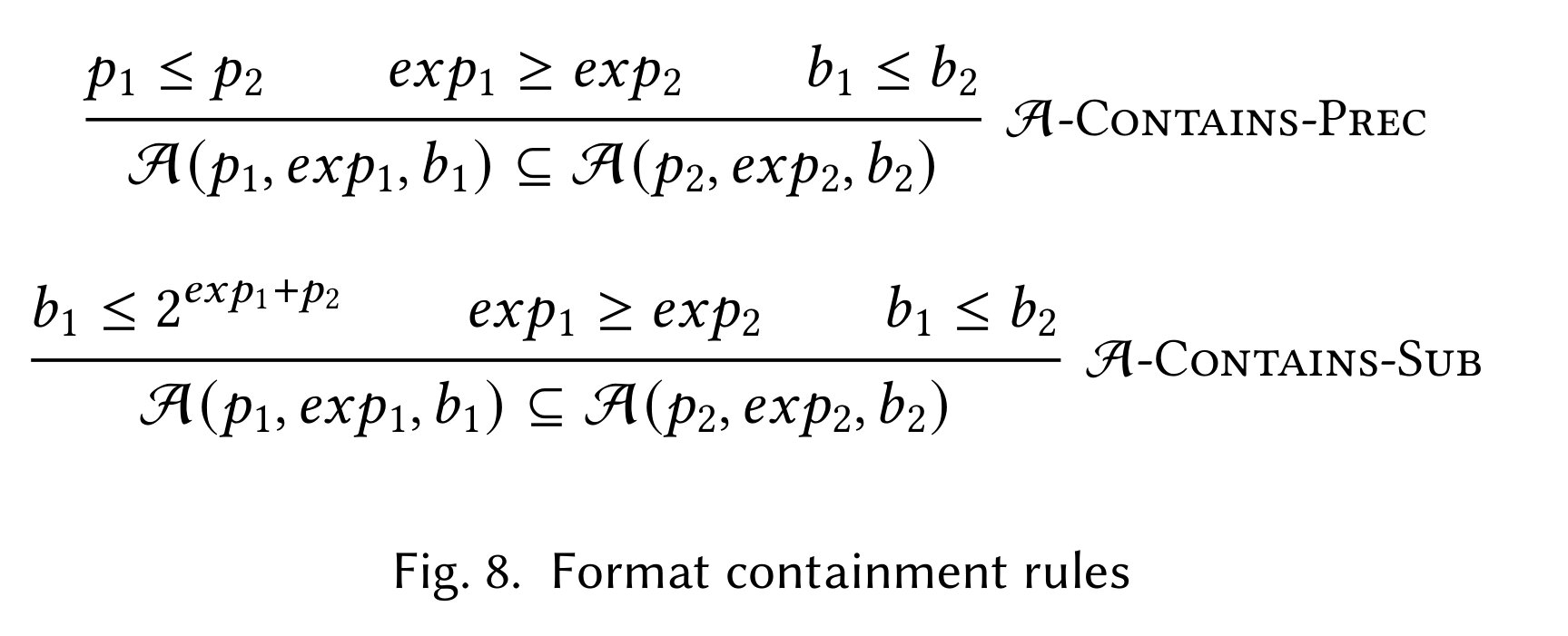
For example,
Figure 8 shows two inference rules for determining
when one number format is a subset of another.
In particular,
the fancy “A” symbol denotes a number format parameterized by
a maximum precision (p), a smallest distance between representable
values (exp), and a maximum representable value (b).
With these rules,
we can check if one number format is a subset of another
from the abstract parameters alone.
With the author response period approaching, I decided it was time to double-check whether my theorems were really correct. Since I’m a programming languages student, I of course turned to proof assistants. The problem: besides taking our proof assistant class (CSE 505), I had very little experience using them, and what experience I did have wasn’t enjoyable.
What was I to do? With all the hype around AI formalizing open conjectures in mathematics (see Erdos problems solved by AI), I decided to let Claude Opus 4.7 help me out. Could it formalize my paper?
Before I dive into my experience, I’d like to thank Zach for funding a Claude Max subscription. I burned through so many tokens; this task definitely would not have been possible without it. I’d also like to thank my coauthors for helping write an amazing paper.
Setup
I decided to use Lean since I believed that the mathlib library would help make proving my theorems easier. I created a repository, installed Lean on my machine, read some documentation, and initialized an empty Lean project. After reading that mathlib takes forever to build manually, I downloaded a pre-compiled version of mathlib to make builds faster.
With an empty project, I started a Claude instance, gave it my paper, and told it to make a plan for translating all of my definitions, theorems, and proofs into Lean. Anecdotally, I find planning mode essential for large tasks. In addition, I made sure the agent wrote a TODO list to a Markdown file within the repository, so it could track its progress even beyond a round of compaction when its context got too large.
## Phase 1 — Dyadic substrate (`Mpfx/Dyadic.lean`)
- [ ] Define `Dyadic := { x : ℝ // ∃ c e : ℤ, x = c * (2 : ℝ) ^ e }`
(via `Subring`, free `CommRing` + `LinearOrder`).
- [ ] Coercion `Dyadic → ℝ` via `Subtype.val`; `@[simp]` lemmas about the coercion.
- [ ] `Zero`, `One`, `Neg`, `Add`, `Sub`, `Mul` instances; closure proofs.
- [ ] `CommRing Dyadic` instance (free via `SubringClass`).
- [ ] `LinearOrder Dyadic` instance (free via `Subring`).
- [ ] Power-of-two helper: `Dyadic.ofIntZpow (c : ℤ) (e : ℤ) : Dyadic` (noncomputable).
## Phase 2 — Abstract format (`Mpfx/Format.lean`)
- [ ] `structure AbstractFormat` with `p : ℕ∞`, `exp : WithBot ℤ`, `b : WithTop Dyadic`, and structural invariants:
- `p_pos : 1 ≤ p` (paper §4.2: `p ∈ ℤ≥1 ∪ {∞}`),
- `not_degenerate : (p ≠ ⊤ ∧ p ≠ 1) ∨ exp ≠ ⊥` (rules out doubly-unbounded `(⊤, ⊥)` and parity-ambiguous `(1, ⊥)` corners),
- `b_nn` (bound non-negative when finite — guarantees `0` is representable).
- *(Future cleanup option: encode `p` directly as `WithTop ℕ+` to drop `p_pos`. Deferred — see "Future work".)*
- [ ] `AbstractFormat.Mem` predicate per the plan.
- [ ] `Membership Dyadic AbstractFormat` instance.
- [ ] `AbstractFormat.extend (F : AbstractFormat) (k : ℕ) : AbstractFormat` — produces `A(p+k, exp-k, b)`.
Used to express the paper's "`F⁺ ⊆ F₂`" hypotheses for the RTO double-rounding rules.
...
I reviewed its TODO list, and told it to go step-by-step. Now, it was time to sit back and watch it generate some Lean.
Smooth Sailing
The agent started on definitions and basic lemmas. It first transcribed my definition of floating- and fixed-point numbers and my abstraction of number formats.
/-- The abstract number format `𝒜(p, exp, b)` from §4.2. -/
structure AbstractFormat where
p : ℕ∞
exp : WithBot ℤ
b : WithTop Dyadic
It wrote a relational definition of rounding.
For example,
the expression roundRTP x y represents
the proposition that x rounds up to y.
While it was working on those early lemmas,
I quickly noticed that it preferred emitting
a whole proof with failing tactics,
reading the build errors,
and then iteratively fixing the failures.
This strategy feels somewhat unnatural:
when manually theorem proving,
I incrementally build the proof from the theorem statement,
inserting sorrys for incomplete cases,
and slowly pushing downwards until it is finished.
By contrast,
the agent emitted a smaller, less refined proof,
then expanded it from the middle to fix
corner cases it hadn’t considered.
Another quirk was its preference
for certain deprecated tactics,
using show instead of change
or push_neg instead of push Not.
I believe these tendencies reveal
the age of its training data:
many of its patterns come from older versions of Lean.
I did not experiment with
telling it to stop using those tactics,
but it would likely have saved time.
/-- **𝒜-Contains-Prec** (Fig. 8). -/
theorem containsPrec {F₁ F₂ : AbstractFormat}
(hp : F₁.p ≤ F₂.p) (he : F₂.exp ≤ F₁.exp) (hb : F₁.b ≤ F₂.b) :
F₁ ⊆ F₂ := by
...
/-- **𝒜-Contains-Sub** (Fig. 8). -/
theorem containsSub {F₁ F₂ : AbstractFormat}
{exp₁ : ℤ} (he₁ : F₁.exp = (exp₁ : WithBot ℤ))
{p₂ : ℕ} (hp₂ : F₂.p = (p₂ : ℕ∞))
(hbprec : F₁.b ≤
((Dyadic.ofIntZpow 1 (exp₁ + (p₂ : ℤ)) : Dyadic) : WithTop Dyadic))
(he : F₂.exp ≤ F₁.exp)
(hb : F₁.b ≤ F₂.b) :
F₁ ⊆ F₂ := by
...
In less than an hour, it proved the theorems from containment rules (Figure 8), the second of which required mild modification, and finished a couple of the double rounding theorems (of six). After some more prodding, it completed three more theorems and made significant progress on the last one. It continued its habits, performing many fix-and-check iterations to complete each proof, and using deprecated tactics that it later went back to clean up. Almost done! Or so I thought.
Counterexample-Guided Refinement
I was double-checking some of its work when I noticed that it inserted additional hypotheses into some of the theorem statements, that is, additional restrictions. Weird, I thought. I interrupted its churn to ask whether it could remove them. It worked for a while, planning out helper lemmas to show that it could prove those additional hypotheses from the original ones I wrote down in my paper, and then trying to prove those helper lemmas.
It occasionally got stuck, reverted to the last stable state, and asked if I really wanted it to work on the lemma. Anthropomorphizing these agents is a bit silly, but if a person did that, I would say they were a bit embarrassed by their inability to prove the lemma.
At some point, it genuinely gave up. I asked if it could prove some other helper lemma instead. After a little while, it came back with a concrete counterexample. Uh oh.
I read its counterexample. The logic checked out, but I realized something: my definition of rounding, specifically rounding to odd, was underspecified, and the behavior the agent inferred for some corner cases was incorrect. After talking to a coauthor, I fixed the issue by defining rounding to odd in those cases and banning a single number format from our abstraction.
I restarted the agent on the same lemmas as before. After a while, it came back with yet another counterexample. This one revealed that rounding to odd has weird behavior when the maximum precision of the format is one, even with the new definition or rounding to odd. There needed to be an additional hypothesis, weaker than what the agent initially inserted, but still a restriction beyond what I put in the paper.
After churning for a while, it finally eliminated the extra hypotheses it inserted. By this point, the agent had spent about half a workday and written nearly 2000 lines of Lean. Of the eight theorems, four were proven, one was proven with a slight modification, two still had extra hypotheses, and one was still unproven.
Slow, Steady Progress
The remaining hours are a blur to me. I told the agent to remove the additional hypotheses. It worked for a long while, got stuck and reverted numerous times, and explained what new changes it needed to implement. My job was to basically say please keep working. At some point, it needed to implement something from my paper that it had initially left out but eventually realized was necessary.
It removed the extra hypotheses from one of the theorems after a number of hours; fixing the other theorem was basically a copy-and-paste job. Finally, it tackled the last unproven theorem.
Despite the many tokens dedicated to refining the already-proven theorems and the many helper lemmas generated by the agent, it took a long time to prove the final theorem. It got stuck numerous times, iteratively moving two steps forward and one step back. This behavior suggested some combination of the agent learning to avoid routes from earlier failed attempts and simply being more adept at smaller-sized tasks.
After nearly two workdays of iterative prompting and burning through over a third of my weekly token limit, the agent proved the final theorem. The codebase had grown to over 5000 lines of Lean. I was happy to discover only a few minor bugs along the way, but was surprisingly exhausted from watching it work.
Discussion
I will summarize my key findings in case they are helpful for others who choose to go down a similar path.
Insight 1
Autoformalization is a smooth process only if (i) your pen-and-paper proofs are correct, and (ii) you have outlined a number of helper lemmas instead of eliding them for clarity. Many of my proofs relied on statements that were imprecise. The agent spent the vast majority of its time uncovering issues in my definitions and exposing corner cases that my underspecified statements hid.
For these tasks, you should write precisely in your papers, not just for readers and reviewers, but for agents consuming them as well. You should provide the agent appendices containing extra descriptions, definitions, and proofs, links to references so it can understand more context, and more.
Insight 2
User expertise is essential for determining whether or not the definitions and theorem statements the agent writes are even correct. This insight is really just a general statement in theorem proving and mathematics at large, even in the absence of AI.
Can you picture what you want to prove? Would you know a bug if you saw it? Have you spent enough time working with your formalization by hand?
Yes, the type checker helps the agent construct these proofs since there is a simple yes/no determination of whether the proof is logically sound. But the agent might transcribe your definitions and theorem statements wrong. It might insert additional hypotheses when a proof is too difficult or just wrong. Ultimately, these responsibilities are still on the user. I very much do not believe that these open conjectures are being solved in a vacuum. In my experience, the agent must be strongly guided.
Insight 3
Using AI for autoformalization is like “bit-blasting” for SMT. In SMT-based verification, the verification expert must be careful with the assumptions they write for their programs and the assertions they want to prove. Sure, you can craft a clever encoding of the problem or select what theories you want to rely on. But at the end of the day, solving the problem might just boil down to the solver bit-blasting your formulas and spinning on a SAT problem until it proves the assertions, comes back with a counterexample, or gives up after a timeout.
Autoformalizing feels somewhat similar. I was responsible for the definitions (the encodings) and the theorem statements (assumptions and assertions). But to get a proof, I just relied on the agent to iteratively figure it out, waiting for it to eventually come back with a “yes, I proved it,” or “here’s a possible counterexample,” or, more often, “I give up.”
Conclusion
Is this the future? We write our papers with informal proofs and only 90% certainty in their soundness, then turn to AI to “do the rest.” It certainly worked for me, and computer numerics, with floating-point numbers and rounding, is no easy field, for people and agents alike. But with rising infrastructure costs, how much longer will this approach be both tractable and cost-effective?
For those who find themselves in a similar position, wanting to formalize their paper but not enough to do it themselves, if you have easy access to many tokens, I’d say give it a try! You might be surprised by what gets generated or be extremely frustrated by bugs or its inability to complete the proof. Hopefully, this blog post gives you some idea of what to expect and some tips for making this process as smooth as possible.
My initial autoformalization is located on this pull request. The current proofs are on the main branch of the same repository.