How does torch.compile work?
Post Metadata
PyTorch is a popular open-source tensor library for machine learning (ML) and scientific computing in Python.
It’s especially popular among the research community because of its active open-source community and its flexibility for experimenting with new ML architectures.
For all of its benefits, it has a clear downfall compared to other ML frameworks like TensorFlow.
It’s slow!
Recent work from the PyTorch team at Meta attempts to bridge the flexibility-performance gap with torch.compile, a feature that speeds up PyTorch code with compilation.
In this blog post, I’ll discuss the motivation for torch.compile and its implementation as a Python-level just-in-time (JIT) compiler called TorchDynamo.
What is PyTorch?
PyTorch is a tensor library for machine learning and scientific computing. It provides a library of tensor operations and linear algebra and numerical optimization routines built on top of them. PyTorch makes it easy to run code on GPUs and accelerate code by plugging in optimized computation kernels like cuBLAS and LAPACK. It’s been widely adopted by ML researchers largely thanks to its flexibility. PyTorch does eager-mode (interpreted) execution, which sets it apart from other graph-mode (compiled) ML frameworks like TensorFlow. The term graph-mode comes from specifying a model’s entire computation graph ahead of time.
Computation graph
A computation graph is a directed acyclic graph with nodes representing computation and edges representing input/output dependencies. For example, consider the program:
a = 1
b = 2
c = a * b + a
which has the following computation graph.
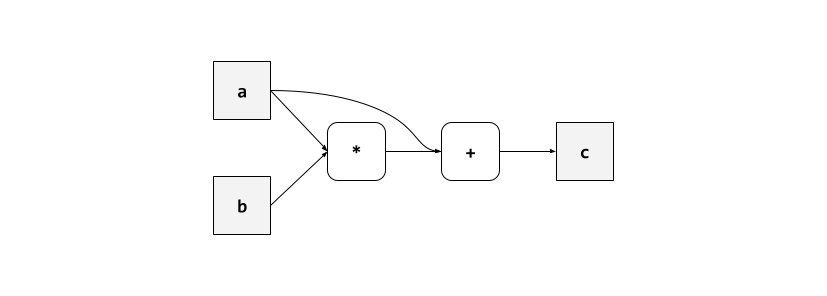
Some ML frameworks require users to specify a model’s computation graph ahead of time, so that a compiler can optimize the model based on its data flow. For example, supposing the program above operates on tensors rather than integers, a ML compiler might fuse together the tensor operations “times” and “plus” into a single function that applies both operations without doing redundant data loading.
PyTorch traditionally doesn’t work this way. It builds computation graphs for tensors at runtime by associating a graph data structure with each tensor and logging operations in the graphs as they occur on the fly. PyTorch calls this eager-mode execution because computation graphs are constructed and interpreted on the fly.
What are the benefits of eager-mode execution?
Eagerly constructing computation graphs has many benefits for programmability. When it comes to building models, programmers aren’t limited to static computation graphs and can encode dynamic behaviors. For example, PyTorch models can
- handle tensors of varying input sizes,
- conditionally skip sub-modules at runtime,
- conditionally pass input data to different sub-modules (e.g. mixture of experts), and
- execute a model in both a training and inference setting (e.g. reinforcement learning).
Another benefit of eager-mode execution is an easier debugging experience, similar to how debugging interpreted programs tends to be easier than debugging compiled programs.
Eager-mode executes operations line by line (like interpreters), so users can directly inspect the state of variables, whereas graph-mode translates programs before execution (like compilers), making it more complicated to inspect intermediate program state and locate the source of errors.
With PyTorch eager-mode, users can debug PyTorch programs like normal Python programs with print statements and interactive debugging tools like pdb and IPython.
What are the drawbacks?
The drawback to this flexibility is performance. PyTorch models are typically slower to train and run compared to their graph-mode counterparts. PyTorch is slow because eager-mode execution only sees one operation at a time, so it can’t perform optimizations across multiple operations like pre-allcoating input/output buffers, fusing operations together, and scheduling CPU-GPU data transfers.
What is torch.compile?
torch.compile is a feature that speeds up PyTorch code through just-in-time (JIT) compilation.
JIT compilers combine the flexibility of eager interpretation and the performance benefits of ahead-of-time compilation by compiling at runtime.
But compiling code at runtime sounds slow, and it can be.
The JIT compiler will incur some performance cost to pause execution and compile a chunk of code at runtime, so that the compiled version can be run instead whenever the code is called in the future.
The compilation cost is amortized, especially when chunks of compiled code get frequently reused.
JIT compilation is apt for machine learning because there is a lot of code reuse, as training and inference involve repeatedly iterating over a model’s forward pass.
torch.compile has two main components.
TorchDynamo is a JIT-compiler that dynamically extracts computation graphs from PyTorch code.
TorchInductor is a compiler backend to TorchDynamo that compiles the extracted computation graphs into optimized C++ or Triton functions.
This blog post focuses on TorchDynamo.
TorchDynamo: Python frame evaluation
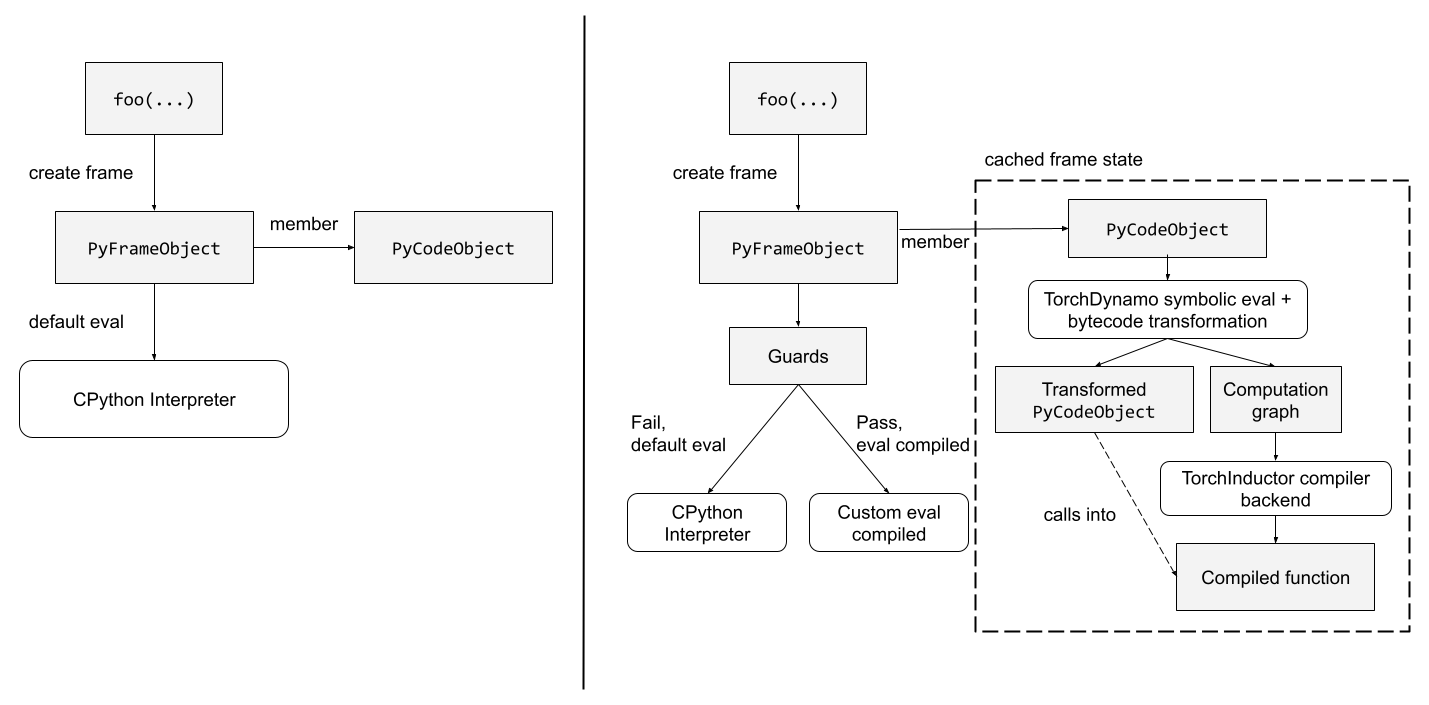
TorchDynamo is a Python-level JIT compiler that hooks into Python’s frame evaluation API and operates on frames. Frames are runtime data structures that store information about the execution state of a function call, including the function’s local variables, arguments, and body. Frame evaluation refers to evaluating the body in the context of the local variables/arguments. Python’s default logic for frame evaluation calls the Python interpreter. TorchDynamo implements custom frame evaluation logic to achieve JIT compilation:
- First, check if the frame should be skipped, and if so default to the interpreter. A frame may be skipped, e.g., due to filename exclusion of Python standard libraries, which will not contain PyTorch operations.
- Next, check if the frame’s body has been previously compiled and cached. If so, execute the corresponding “guard” function and if it passes, run the compiled code (otherwise, run the interpreter). Guards are functions which check properties of a frame’s input arguments that must be met in order to re-use previously compiled code. Guards are necessary because a compiled artifact may depend on, e.g., inputs being tensors of certain shapes.
- If the guard fails or there is no cached compilation, then compile the frame and generate a new wrapper function that runs the compiled code (see the next section). Also generate a guard function (not discussed in this post). Cache the two functions in the frame object and then call into the wrapper.
The diagram below shows how TorchDynamo modifies the default behavior of Python (shown on the left) according to the steps above.
The diagram is heavily inspired by Fig. 1 of PyTorch 2.
Now we’ve seen the flow of the JIT compiler, but there are some missing pieces:
- How does TorchDynamo extract computation graphs from Python frames?
- How do the computation graphs get transformed into compiled code?
I will discuss (1) in the next section. (2) is the job of TorchInductor, a compiler backend that transforms computation graphs into optimized C++ or Triton functions. TorchInductor is left for a future blog post.
TorchDynamo: symbolic evaluation + bytecode translation
TorchDynamo extracts computation graphs from Python frames via symbolic evaluation. Symbolic evaluation is a general program analysis technique that interprets a program on symbolic inputs. It builds up an expression that represents the program’s computation in terms of symbolic variables.
TorchDynamo uses symbolic evaluation to build computation graphs of PyTorch operations from Python frames. TorchDynamo uses FX graphs as a data structure to represent computation graphs. TorchDynamo’s symbolic evaluation engine interprets one Python bytecode instruction at a time on symbolic input tensors. Python bytecodes are an intermediate representation that Python gets parsed into before interpreting.
As TorchDynamo symbolically evaluates bytecode instructions, it accumulates a computation graph that records each of the frame’s PyTorch operations. Once it reaches the end of a frame, it passes the computation graph to TorchInductor to compile it into optimized C++ or Triton code. Then, TorchDynamo generates a new wrapper function that calls into the compiled code, then reconstructs the behavior of the original code by updating the local stack state and performing any side effects (for more details, see Sec. 3.7 of PyTorch 2).
The explanation so far has skipped an important case: symbolic evaluation cannot handle every Python bytecode instruction. For example, instructions that need to materialize data, e.g. to print a value or do data-dependent control flow, cannot be symbolically evaluated as symbolic variables have no underlying data to materialize.
When the symbolic evaluation engine hits an instruction that it can’t handle, it creates a “graph break”. At a high level, a graph break is like reverting back to interpreted mode. TorchDynamo compiles and runs code for a partial graph, then interprets the instruction that can’t be compiled, and then resumes trying to compile the remaining code after the break.
To instrument a graph break, TorchDynamo first passes a partial graph (the computation graph that has been accumulated up to this point) to TorchInductor to get compiled. Then, it generates a new wrapper function that (1) runs the compiled code, then (2) interprets the bytecode instruction that can’t be compiled, then (3) calls a continuation function, which runs the remainder of the original code. All the live variables in the original frame at the point of the graph break are passed along into the continuation. The continuation design enables TorchDynamo’s analysis to be recursively applied after graph breaks; when Python executes a continuation function, TorchDynamo will attempt to compile the function just like any other Python frame.
Let’s see an example.
1: import torch
2:
3: def foo(a: torch.Tensor, b: torch.Tensor):
4: c = a - b
5: if c < 0:
6: c = -c
7: else:
8: c = c * 2
9: return c
10:
11: foo = torch.compile(foo)
12: foo(torch.tensor(1.0), torch.tensor(2.0))
When foo gets called on line 11, TorchDynamo compiles the frame associated with the function call.
The frame includes the body of foo and the values of the arguments.
We can turn logging on to see the bytecode that TorchDynamo’s symbolic evaluation engine sees by setting export TORCH_LOGS="+bytecode".
Before any compilation, the bytecode for foo looks like:
4 0 LOAD_FAST 0 (a)
2 LOAD_FAST 1 (b)
4 BINARY_SUBTRACT
6 STORE_FAST 2 (c)
5 8 LOAD_FAST 2 (c)
10 LOAD_CONST 1 (1)
12 COMPARE_OP 0 (<)
14 POP_JUMP_IF_FALSE 24
6 16 LOAD_FAST 2 (c)
18 UNARY_NEGATIVE
20 STORE_FAST 2 (c)
22 JUMP_FORWARD 8 (to 32)
8 >> 24 LOAD_FAST 2 (c)
26 LOAD_CONST 1 (1)
28 BINARY_ADD
30 STORE_FAST 2 (c)
9 >> 32 LOAD_FAST 2 (c)
34 RETURN_VALUE
First, TorchDynamo creates symbolic (fake) input tensors for a and b which both have the shape torch.Size([]), which is the shape of a zero-dimensional tensor (a single number).
TorchDynamo starts by symbolically evaluating the bytecode instructions corresponding to c = a - b and builds a computation graph for the operation.
When it hits the COMPARE_OP instruction, the symbolic evaluation engine realizes that it can’t do a data-dependent jump and triggers a graph break.
We can turn on logging to see when TorchDynamo creates a graph break by setting export TORCH_LOGS="+bytecode,+graph_breaks".
It reports:
Graph break in user code at test.py:5
Reason: Data-dependent jump
User code traceback:
File "test.py", line 5, in foo
if c < 1:
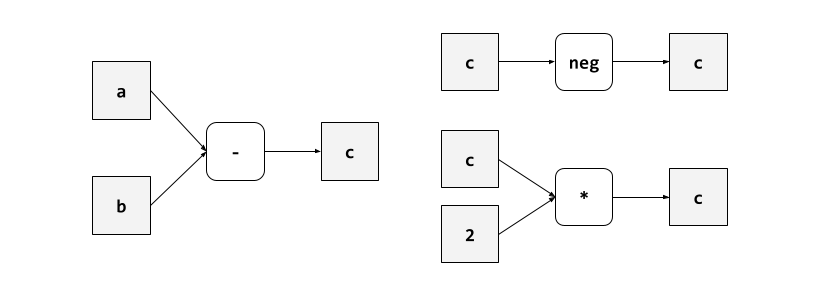
TorchDynamo compiles the partial graph (corresponding to c = a - b) and generates two continuations, one for each branch of the data-dependent conditional.
The modified bytecode looks like:
0 LOAD_GLOBAL 0 (__compiled_fn_1)
2 LOAD_FAST 0 (a)
4 LOAD_FAST 1 (b)
6 CALL_FUNCTION 2
8 UNPACK_SEQUENCE 2
10 STORE_FAST 2 (c)
12 POP_JUMP_IF_FALSE 22
14 LOAD_GLOBAL 1 (__resume_at_16_2)
16 LOAD_FAST 2 (c)
18 CALL_FUNCTION 1
20 RETURN_VALUE
>> 22 LOAD_GLOBAL 2 (__resume_at_24_3)
24 LOAD_FAST 2 (c)
26 CALL_FUNCTION 1
28 RETURN_VALUE
The original bytecode is transformed into a bunch of function calls separated by some data-dependent control flow. In particular,
__compiled_fn_1corresponds to the compiled partial graph forc = a - b,__resume_at_16_2is a continuation function that runs the code in the true branch, and__resume_at_24_3is a continuation function that runs the code in the false branch.
When the new bytecode executes, the continuations __resume_at_16_2 and __resume_at_24_3 get compiled by TorchDynamo just like any other function, resulting in three partial graphs:
Conclusion
I hope you thought this was cool!
I think this is an exciting technique for optimizing ML systems, especially ones that have dynamic runtime characteristics.
For example, torch.compile can cache different versions of compiled code optimized to different input tensor shapes.
This can adapt a model’s execution to varying input sizes during training or inference.
torch.compile can also compile partial graphs for separate sub-modules of a model that are connected by data-dependent control flow (e.g., routing in mixture of experts).
This enables local computation graph optimizations even when a global static computation graph does not exist.
Here are some resources for further reading.
- torch.compile [tutorial] [paper]
- TorchDynamo deep dive [article] [video]