Finding and fixing accessibility issues with axe
Post Metadata
Hi friends! I’m back to discuss more accessibility improvements we’ve made to the PLSE website: how we found more issues, how we fixed them, and how we’ll (hopefully) not make these same mistakes in the future! In particular, this post touches on running automated browser tests across our entire website to flag specific types of accessibility issues. Along the way, we’ll learn about some specific web accessibility standards and how to implement them not-poorly!
This post continues the line of work discussed in “Improving our website’s accessibility with static analysis + CI”, but it’s not strictly necessary to have read that post. I’ll only assume that readers have some knowledge of HTML, CSS, & JS, and why accessibility is important. Though you may get more out of this post if you’re familiar with web accessibility standards, browser automation, GitHub CI/CD, and/or Ruby test suites.
The rest of this post is roughly split up into four parts:
- brief background on web standards, browser automation tooling, and static site generator infrastructure
- in brief: a Capybara + axe pipeline (thanks to Michael Ball)
- what errors did we find? how did we fix them? (the meat of the post)
- what’s next?
This post discusses a CI pipeline built by Michael Ball for the Berkeley CDSS Instructional Tools group’s website template. That template is in turn a custom fork of Kevin Lin’s Just the Class, which is in turn a template for Just the Docs (which I maintain — I know, it’s a long chain). Huge thank you to Michael; I’m hoping to upstream his work (see: his open PR to Just the Docs) to the many users of Just the Docs soon!
Context (in three parts)
This next section is entirely context. First, it defines some relevant accessibility organizations and standards (the ADA, WAI, WCAG). Then, it briefly explains some browser automation tooling (axe on top of Capybara and Selenium) and closes with a brief explanation of Jekyll (our static site generator). You’re free to skip them any of these sections if you’re familiar with these terms!
Standards (WCAG and the ADA)
The World Wide Web Consortium (W3C) is a non-profit and international standards organization that makes the world wide web work. Among other things, they host and edit the HTML and CSS specifications. One key player in the digital accessibility space is the W3C’s Web Accessibility Initiative (WAI), which authors the Web Content Accessibility Guidelines (WCAG): a standard on making web content more accessible for people with disabilities.
There are several versions of the standard: WCAG 2.0 (2008) is the latest major version, with backwards-compatible versions 2.1 (2018) and 2.2 (2023). A major revision (WCAG 3) is in the works, though it is still a draft (at the time of writing). There are also different levels of conformance to the spec (A, AA, AAA). Folks will often use “WCAG” as a catch-all for the WAI, the general idea of WCAG standards, or a specific version/level; in this post, we’ll strictly treat “WCAG” as a technical standard and refer to the specific version and level when possible.
In April 2024, the Department of Justice (DOJ) updated how the Americans with Disabilities Act (ADA) treats web and mobile content (informally, the “web rule”). The updated regulation specifically cites WCAG 2.1 AA as the legal standard that local and state governments have to meet. This includes the University of Washington (!!), and UW’s deadline to meet this standard is April 24, 2026. As a result, the bulk of this post will be about WCAG 2.1 AA. For more on the updated regulation (formally: Title II of the ADA), see the ADA Fact Sheet and the DOJ Press Release.
Browser Automation (and axe)
People tend to think of web browsers as a singular piece of software that lets you navigate the web. A programmer might view them as a singular piece of software that renders HTML, CSS, and JS to a graphical interface (or to a screen reader). A helpful separation for us is splitting up the execution of HTML, CSS, and JS — which includes things like page layout algorithms, deciding the color of text, and executing JS that modifies a page — with the actual process of putting pixels on a screen. When answering questions like “does the login button on my app work” or “does this text have sufficient color contrast”, we only need the execution. Running the browser without a graphical interface — often called “headless” — makes browser automation significantly easier to implement and more performant.
All major browser engines in use today are open-source. As a result, there’s a plethora of browser automation and test frameworks built on top of popular browsers. Open-source browser automation tooling has grown over the past decade, coming from corporate investment (Google, Microsoft, and Meta are big players), standards bodies (see: W3C WebDriver), and smaller entrants like BrowserStack or SauceLabs. This post uses Capybara, a high-level Ruby library for writing web application tests. Under the hood, Capybara uses Selenium’s WebDriver, which you can roughly think of as bindings for a headless web browser. If you’re curious, you may also be interested in Playwright, Puppeteer, Cypress, or Jasmine — all of which roughly operate at the same level as Capybara. These tools are essentially the industry standard for front-end application testing.
A big player in digital accessibility is Deque Systems, who have built their business around web accessibility services. Notably, they’ve open-sourced many of their tools. The most famous is axe-core (also called “axe” — though strictly speaking, that’s a suite of products and tools Deque produces), an accessibility rules engine that audits web page accessibility (with a focus on differentiating between WCAG 2.0, 2.1, 2.2 across different levels of conformance). It plays very nicely with most popular browser testing frameworks, including Capybara and Selenium!
Running accessibility tests on a headless browser is significantly more powerful than the static analysis approach described in the previous post. Instead of being limited to what we can infer from a static context, we can actually interact with a page “like” a real user with a browser — because we are using a real browser!
Quick plug: if you’re interested in more about browser engineering, check out Pavel (a PLSE alum!) and Chris’s wonderful Web Browser Engineering book.
Static Site Generators (and Jekyll)
A static site generator (SSG) is software that compiles source code (typically a blend of human-readable languages like Markdown and plain-old HTML and CSS) into static web pages. SSGs offer many benefits compared to writing just HTML and CSS, while avoiding the complexity of a server-side application or a CMS like WordPress. For example, SSGs often embed lightweight templating languages for improved expressivity (e.g. site variables for repeated content across pages or loops for repeated content on a page).
There are many, many great SSGs out there. PLSE’s website is powered by Jekyll, which is written in Ruby and has strong ties to GitHub (historically a Ruby shop). Among other things, it is also the default GitHub Pages SSG. Jekyll has a large ecosystem and set of plugins; it has also influenced other popular SSGs (e.g. Hugo, Eleventy, and MkDocs).
The approach described in this post should work for any static website (SSG or not). The choice of tooling is mostly related to the ecosystem surrounding Jekyll and Ruby. While it’s still possible to use Capybara with any static site generator, it may make more sense to use a test suite and/or web application framework native to that language (which almost certainly exists).
The CI Pipeline
The Argument for CI
Checking websites for accessibility is a challenging task! The PLSE website is no exception. A non-exhaustive list of reasons:
- there are many pages (252 as of publishing this post) — checking these manually would be time-consuming!
- when using a static site generator, much of the structure of the page is abstracted away from you. Abstractions can make it harder to reason about accessibility; for example,
- you may not realize that you’ve skipped a page heading, because the website theme (sometimes) automatically adds an
<h1> - changing a stylesheet, layout, or component may have far-reaching impacts beyond the page you were trying to fix
- you may not realize that you’ve skipped a page heading, because the website theme (sometimes) automatically adds an
- like most academic groups,
- the site has many different authors, with varying levels of expertise in web development and accessibility
- there is no dedicated full-time web developer who maintains the site (or even “owns” all the content)
At the scale of our group and website, it doesn’t make sense to manually audit each page again and again. Less obviously, it also doesn’t make sense to do a “yearly accessibility audit” (or audits over other infrequent periods): significant changes will be made between audit periods, and it will be challenging to fix tens to thousands of errors once a year.
Instead, we should take a page out of traditional software engineering playbooks and use continuous integration (CI)! In our case, we should run accessibility tests every time anybody makes a change to the site. We’ll catch errors early on and fix them as they pop up, rather than waiting to resolve an enormous accessibility debt once a year. As CI has become cheaper (in both monetary and runtime cost) and accessibility tools have improved, running accessibility checks on-demand has become an increasingly achievable goal.
The Actual Action (in brief)
Luckily many other folks have thought running accessibility checks for SSG content, including Michael Ball (at UC Berekeley EECS). Their group use a fork of a Jekyll theme that I maintain, and their team has done a great job in making their theme more accessible. Earlier in 2024, he submitted a pull request titled “Add a11y specs” which implements a GitHub Action that:
- builds every page in a Jekyll site
- uses a sitemap generated by jekyll-sitemap as the “source of truth” for the list of all generated pages
- for each page in the sitemap,
- loads the page in headless Chrome via Capybara (at
1280pxwide) - uses the
be_axe_cleanmatcher on the entire page to check for:- WCAG 2.1 compliance (specifically, using the WCAG 2.0 A + AA and WCAG 2.1 A + AA axe-core tags)
- “best-case” compliance (specifically, using the WCAG 2.2 AA,
best-practice, andsection508axe-core tags)
- if the page has at least one error, takes a screenshot of the page (better than always taking a screenshot — which is expensive!)
- loads the page in headless Chrome via Capybara (at
- packages the test results up in a nice HTML page
This action works quite well, and I’ve essentially copied it into the PLSE website! The last step is particularly helpful — when a part of the site doesn’t meet the standard, you can easily troubleshoot exactly what it is (based on the selector, generated file, and screenshot), try to fix it, and then re-run the process. On my M2 laptop, the entire run takes about 2 minutes (for 252 pages) — which is not instant, but not prohibitively slow.
I’m intentionally keeping this section short since it’s mostly not my work. You should take a peek at the “Add a11y specs” PR for more details — and hopefully I’ll be able to talk more about his work with my Just the Docs hat on soon!
Finding and Fixing Errors
Other than some minor typo and configuration fixes, it was easy to get Michael’s CI pipeline to work with the PLSE website. However, before we could add the pipeline to the main branch of our repository (and deploy it “across” PLSE), I needed to fix all of the issues flagged by the tool, both so:
- developers don’t find the check noisy, and will know that a test failure indicates that something is wrong with their change
- we can fix all of these accessibility issues that we’ve just found!
I first demoed the check in September, resolved almost all the issues by October (and deployed it on October 9th), and have monitored it since. Things have gone relatively smoothly since then, though there are still improvements to make.
Let’s talk about all the errors that I found and fixed!
The Data
Here’s a table summarizing all the various WCAG 2.1 errors found when we first added the check (with links to the axe rule that flagged it):
| error | content type | pages affected | total instances (across all pages) | fix sketch |
|---|---|---|---|---|
| color contrast | main text | 97 | 2512 | in almost all cases: change the foreground color to be darker |
| color contrast | code | 8 | 634 | pick a new syntax theme |
| deprecated ARIA role | footnotes | 3 | 10 | see fixing footnotes |
| iframes with no accessible title | embedded video | 23 | 23 | add a title |
| link without discernable text | links | 5 | 9 | add screenreader-only text for decorative image links, or remove erroneously-generated links |
And, WCAG 2.2 errors:
| error | content type | pages affected | total instances (across all pages) | fix sketch |
|---|---|---|---|---|
| document has no landmark | page layout | 232 | 232 | ensure that all pages have a <main> |
| page content outside of landmark | page layout | 232 | 1501 | fix landmark-one-main (all content is otherwise contained in a landmark already!) |
| touch targets are too small | links | 11 | 78 | make non-text links (typically images) larger |
| empty table header | tables | 6 | 37 | either add a table header (for tabular data), or use an alternate layout format (when using tables just for layout) |
| incorrect heading order | heading | 87 | 87 | fix invalid heading order (and re-style when appropriate); I caught most of these in our last post! |
| misused ARIA role | footnotes | 3 | 10 | see fixing footnotes |
page is missing h1 |
headings | 54 | 54 | fix lack of <h1> for colloquia and internal pages |
Your immediate reaction is probably, woah, that’s a lot of errors! Your second reaction is probably, “many of these must be the same error” — how serious are these issues for a user, and how easy is it to fix?
The answer to those two questions is markedly different:
- for a disabled user, each of those errors is a distinctly affects their experience.
- for example, each page without a landmark is harder to navigate,
- and each code block with poor contrast is hard to read,
- and each page with wrong heading order generates an incorrect screenreader table of contents
- but, we can take advantage of static site generators (and other machine-editing tools) to fix many of these errors en masse (and then verify fixes manually).
Most of the fixes were low-hanging fruit: they were relatively mechanical, and outside of reading the linked error message, didn’t require significant knowledge of accessibility standards or expert web development. They did mostly require an eye for detail (and in some cases, the willingness to dig through many, many pages of content). Some rule pages also have simple-English explanations of the algorithm for the check, which is helpful!
I’ll touch on two fixes that warrant a bit more explanation!
Worked Example: Color Contrast for Code Highlighting
Color contrast for text is a common accessibility issue in many websites (for a relatively approachable introduction, see WebAim’s Contrast and Color Accessibility article). Some of the issues that I found were common ones I’ve seen as a web developer, including:
- gray text that’s too light, and contrasts poorly with a white background — very common with blockquotes, footnotes, and subtitles
- blue links that are slightly too light, and similarly contrasts poorly with a white background
Fixing these isn’t too tricky; my typical approach is to rely on a contrast checker and pick a different foreground color that preserves the “feel” of the original color while also meeting the standard.
However, a less common (but still important!) application is syntax highlighting. On one hand, syntax highlighting is incredibly helpful for novice and expert programmers alike! On the other hand, many syntax highlighting themes have major color contrast issues. In addition, many developers don’t really know how the highlighter works (or how the colors are picked). For a visual example, here’s a block of code from an old version of Ryan’s wonderful post “Simplifying Addition and Multiplication in Polynomials”:

Several of these colors don’t contrast well (and don’t meet the standard). A colorblind or low-vision reader (or, someone looking at this code on a bad projector — a daily occurrence!) may not be able to read:
- most notably, the comments — which are a gray on gray (specifically,
#999988on#f8f8f8— which has a contrast ratio of 2.72, much lower than the 4.5 for WCAG 2.1 AA) - less notably, the light blue keywords for
dictandlist(specifically,#0086B3on#f8f8f8— which has a contrast ratio of 3.9) - many other examples — if you have five minutes, take a look at the Pygments styles page; are any hard to read on your monitor?
So, how do we fix this?
Jekyll’s default syntax highlighter is Rouge, which converts markdown blocks (with a language hint) into tokenized HTML code (with CSS styles applied depending on the type of token, based off of Python’s Pygments). For Ryan’s example, it takes in markdown like this:
```python
def collect_like_terms(add: Add):
like_terms: dict[Node, list[Coeff]]
like_terms = {}
for monomial in add:
# This helper does:
# y * 2 => (y, 2)
# 3 * x**2 => (x**2, 3)
(term, coeff) = split_coeff(monomial)
# put the coefficients of "like terms"
# into the same list
like_terms[term].append(coeff)
return like_terms
```
and creates HTML that looks like this:
<div class="language-python highlighter-rouge"><div class="highlight"><pre class="highlight"><code><span class="k">def</span> <span class="nf">collect_like_terms</span><span class="p">(</span><span class="n">add</span><span class="p">:</span> <span class="n">Add</span><span class="p">):</span>
<span class="n">like_terms</span><span class="p">:</span> <span class="nb">dict</span><span class="p">[</span><span class="n">Node</span><span class="p">,</span> <span class="nb">list</span><span class="p">[</span><span class="n">Coeff</span><span class="p">]]</span>
<span class="n">like_terms</span> <span class="o">=</span> <span class="p">{}</span>
<span class="k">for</span> <span class="n">monomial</span> <span class="ow">in</span> <span class="n">add</span><span class="p">:</span>
<span class="c1"># This helper does:
</span> <span class="c1"># y * 2 => (y, 2)
</span> <span class="c1"># 3 * x**2 => (x**2, 3)
</span> <span class="p">(</span><span class="n">term</span><span class="p">,</span> <span class="n">coeff</span><span class="p">)</span> <span class="o">=</span> <span class="n">split_coeff</span><span class="p">(</span><span class="n">monomial</span><span class="p">)</span>
<span class="c1"># put the coefficients of "like terms"
</span> <span class="c1"># into the same list
</span> <span class="n">like_terms</span><span class="p">[</span><span class="n">term</span><span class="p">].</span><span class="n">append</span><span class="p">(</span><span class="n">coeff</span><span class="p">)</span>
<span class="k">return</span> <span class="n">like_terms</span>
</code></pre></div></div>
The n, k, p, nf, and other seemingly-incomprehensible CSS classes are shorthands for Pygments tokens; any Pygments-compatible stylesheet then applies the relevant colour rules. Instead of tweaking each individual CSS class for each token (which can be painstaking), we should just pick an accessible syntax highlighting theme.
Luckily, we are far from the first people to run into this problem. Many accessible color themes exist, but I ended up choosing the WCAG 2.1 AAA-compliant GitHub Light theme from the wonderful BSD-licensed accessible-pygments project. Now, Ryan’s code looks like this:
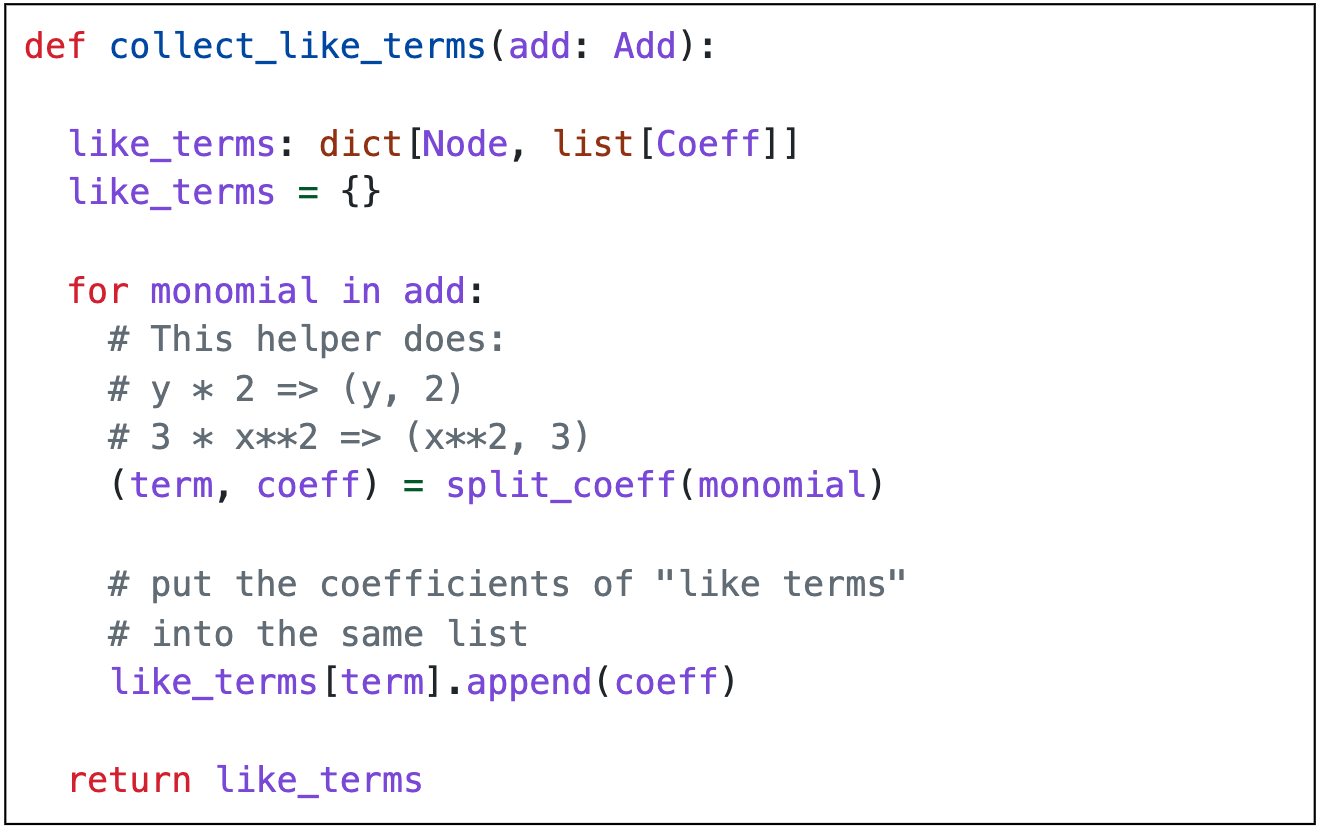
(or, see it on the post itself, under “Now we’re ready for…”)
The changes to the gray for the comments (#6e7781) are subtle, but make enough of a difference to meet the WCAG 2.1 AA guidelines and show up better on a bad projector. The keywords and variable names are now a bright, high-contrast purple (#8250df). Both of these contrast better against an (admittedly harsher) pure white background (#ffffff).
If you’re running a Jekyll site yourself, I would highly encourage you to look into changing the default syntax highlighting theme: most themes not explicitly designed for accessibility (including the Rouge default) have some contrast issues.
Worked Example: Colloquia Pages (or the case for storing structured data)
PLSE has a rich archive of colloquia talks from years past. While the list itself isn’t updated frequently, it’s still important archival content. Unfortunately, the many colloquia pages all had similar (but not identical) accessibility issues.
Each colloquia page is a standalone markdown file (that Jekyll converts to HTML). Here’s one example for our very own René’s 2017 talk (with long paragraphs omitted for brevity):
---
content_type: md
layout: default
title: UW PLSE Visitor - René Just
permalink: /colloquia/170628-rene-just.html
---
### [René Just](https://people.cs.umass.edu/~rjust/)

<!-- NOTE: the next 3 lines end with spaces to get line breaks in md!! -->
*Learning from Program Context to Predict Effective Program Transformations*
July 5, 2017 at 3:30pm
[CSE 305](http://www.washington.edu/maps/#!/cse)
### Abstract
Program transformations or program mutations are an essential
component of many automated techniques in software engineering [...]
### Bio
René Just is an Assistant Professor at the University of
Massachusetts, Amherst [...]
### Talk
(the data between the --- and --- is the “front matter” for the page; Jekyll can use this data when rendering the page)
It’s hard to know exactly what accessibility issues exist without seeing the final output HTML; but, you can see that:
- this page has no clear title and/or
h1(and it turns out the layout doesn’t render one either). “René Just” (or that and his talk name) are probably the best match. - René’s name has the same heading hierarchy as “Abstract”, “Bio”, and “Talk” — when in reality, those three should probably be subheadings!
- the alt text of
visitor-photois not very helpful. - the items under René’s name have structure (e.g. the title of his talk, the time and date, and the location) — but it’s not immediately obvious (and this structure isn’t visible to a screenreader). Among other things, tabbing over the “CSE 305” link provides no indication as to what the link is to — how would a non-UW visitor know that CSE 305 is a room location? (maybe it’s a class?)
- there is no content under “Talk” (that’s not a typo), but the heading is present anyways — that’s confusing!
Each colloquia page roughly follows the same structure, though some vary. Some don’t have a ### Talk heading when there’s no recording, and some do; for example, here’s Daniel Rosenwasser’s old colloquia entry:
### Talk
<iframe width="560" height="315" src="https://www.youtube.com/embed/IIKSqFdgC8c" style="border: none;" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
A screenreader user navigating through this page has little context on what the iframe represents: could it be a recording of the talk, or a link to a paper, or something else?
The high-level insight is that all of these markdown pages have structured data, but they encode them in an unstructured way. A lack of structure makes making batch-level changes (like fixing heading order) quite hard: I’d need to go to each of the >50 colloquia pages and manually fix their heading order, and then do the same for all the other accessibility issues that I pointed out. In theory, this is the type of problem that static site generators solve — but because our data isn’t stored in a machine-readable format (e.g. a YAML file in the Jekyll world), I can’t take advantage of these features.
After realizing just how much work manually resolving these would be, I instead chose to:
- write a series of regexes that would (roughly, but not perfectly) pull out individual pieces of data (e.g. the talk title) and add them to the page’s front matter, in-place
- manually audit and fix issues from the regex (~ 10 total)
- write a Jekyll layout for colloquia (which you can think of as a function that takes in data and spits out HTML/CSS)
- apply the accessibility fixes once to the layout
- finally, manually check each page to make sure that overall look was preserved
- ponder if this actually saved me time (see: xkcd #1319: automation)
This approach worked reasonably well. Now, René’s talk page looks like this:
---
layout: colloquia
title: UW PLSE Visitor - René Just
permalink: /colloquia/170628-rene-just.html
visitor:
name: René Just
url: https://people.cs.umass.edu/~rjust
photo: img/rene-just.jpg
talk:
title: "Learning from Program Context to Predict Effective Program Transformations"
datetime: July 5, 2017 at 3:30pm
location: "[CSE 305](http://www.washington.edu/maps/#!/cse)"
---
## Abstract
{: .h3 }
Program transformations or program mutations are an essential
component of many automated techniques in software engineering [...]
## Bio
{: .h3 }
René Just is an Assistant Professor at the University of
Massachusetts, Amherst [...]
Outside of the abstract & bio, the rest of the content is in the front matter. In the colloquia layout, I can take advantage of this data and render pages with structural annotations:
<h1 class="h3">
{% if page.visitor.url %}
<a href="{{ page.visitor.url }}">
{{ page.visitor.name }}
</a>
{% else %}
{{ page.visitor.name }}
{% endif %}
</h1>
<img class="visitor-photo" src="{{ page.visitor.photo }}" alt="Photo of {{ page.visitor.name }}">
<h2 class="text-paragraph" style="padding: 0; font-style: italic; display: inline-block; line-height: 1.4;">
<span class="sr-only">Talk: </span>{{ page.talk.title }}
</h2>
<br>
<dl style="display: inline-block;">
<dt><span class="sr-only">Date and Time</span></dt>
<dd>{{ page.talk.datetime }}</dd>
<dt><span class="sr-only">Location</span></dt>
<dd>{{ page.talk.location | markdownify }}</dd>
</dl>
{{ content }}
{% if page.talk.recording %}
<h2 class="h3">Talk <span class="sr-only">Recording</span></h2>
<iframe
title='PLSE: {{ page.visitor.name | xml_escape }}, "{{ page.talk.title | xml_escape }}" Recording'
width="560" height="315" src="{{ page.talk.recording }}"
style="border: none;" allowfullscreen>
</iframe>
{% endif %}
I could then batch-fix the heading order, add a title to the iframe, and only render the talk header if it exists. I also encoded a bit more structure into the date and time, and added screenreader annotations (using a CSS class similar to Tailwind’s screenreader-only CSS) to clearly label and disambiguate the talk title, date/time, location, and recording.
Along the way, I fixed a handful of bugs (broken links, typos, etc.) that hopefully made the colloquia pages a more effective archive! (though, there are still things to improve — e.g. the alt text)
Bigger picture, the lesson to learn here is: if your website has duplicated content (like the colloquia pages) in a highly structured way, it pays dividends to store that data properly, and render it into HTML later; it’s then easier to make larger changes, accessibility or otherwise.
An Aside: Fixing Footnotes
One potentially tricky part of using markdown to generate web content is peering behind the abstraction — and in particular, how markdown maps to HTML. It’s particularly hard to make rendering changes within the confines of an SSG’s public API (e.g. for the GitHub Pages gem, you can’t execute arbitrary Ruby code — so most generation tweaks are off the table), and I was dreading having to fix problems at this level of abstraction. When I first drafted this post in early September, it was looking like I had to — but then the community responded!
In particular: kramdown is the Ruby-based markdown parser that Jekyll uses to convert markdown to HTML. An extension it provies (on top of Markdown) is the footnotes/endnotes feature1. You can define a footnote inline, similar to a link:
footnotes/endnotes feature[^example].
alongside a corresponding footnote definition:
[^example]: Wow, isn't this meta?
Kramdown will then automatically handle numbering, make the superscript1 with a link to the footnote, as well as the “return” link (including multiple returns, like the example used in this post). The kramdown version for this site (2.4.0, released in 2022) generates the following HTML:
<sup id="fnref:example" role="doc-noteref">
<a href="#fn:example" class="footnote" rel="footnote">1</a>
</sup>
and the footnote definition looks like:
<div class="footnotes" role="doc-endnotes">
<ol>
<li id="fn:example" role="doc-endnote">
<p>Wow, isn’t this meta? <a href="#fnref:example" class="reversefootnote" role="doc-backlink">↩</a> <a href="#fnref:example:1" class="reversefootnote" role="doc-backlink">↩<sup>2</sup></a></p>
</li>
</ol>
</div>
Using ARIA roles (the role attribute) is tricky (and many developers are unfamiliar with them)! All roles prefixed with doc- are defined in the Digital Publishing (DPUB) WAI-ARIA spec. In version 1.1 (released in 2024) they’ve deprecated the doc-endnote role; to quote the spec:
The doc-endnote role was designed for use as a list item, but due to clarifications in the WAI-ARIA specification, it is not valid as a child of the list role. As the doc-endnotes role already identifies a section of endnotes, authors are instead advised to use the list and listitem roles when native HTML elements cannot be used to structure the entries.
Oh no! Our generated markdown applies the doc-endnote role as a child of a <ol>, which has the list role. Even though the <li> has the listitem role by default, the explicit role attribute overrides this meaning. Incorrect use of the role attribute can have adverse accessibility impacts, though it depends on how the user agent (in this case, the screenreader) interprets the above HTML (and how closely it conforms to the spec). It’s not clear to me exactly how prevalent this issue is now, since these spec updates were fairly recent (and some user agents, like VoiceOver, seem to skip over the clashing role issue).
However, in the last month (i.e., after I started writing this post) this was fixed: starting from kramdown 2.5.0, kramdown now no longer applies the doc-endnote attribute to the li (but keeps everything else the same). That release also fixed another unrelated minor accessibility issue with footnotes. In the previous example, the doc-noteref role should be applied to the link itself (i.e. the <a>), rather than enclosing elements (i.e. the <sup>); kramdown now also does this too. It will take some time for these two changes to propagate through the Ruby ecosystem, especially as the GitHub Pages gem lags behind jekyll. Huge thanks to Thomas Leitner for his continued work on kramdown!
What’s Next?
There’s always more to do! Outside of the fact that automated tests can never fully capture the spectrum of disability, there are quite a few things we can do to make this system more robust — as well as apply our learnings elsewhere.
Tuning and Parameters
One limitation of the current approach is that we’re only evaluating pages on a screen width that emulates a laptop (specifically, at 1280px wide). This misses potential layout shifts across different screen widths (e.g. a mobile phone, a tablet, or an ultrawide monitor). The PLSE site doesn’t use much responsive design, but there are elements of it, and for full coverage we should be evaluating across a multitude of screen widths.
We could just run tests for multiple screen widths in parallel. But, there’s a big catch: the entire CI pipeline takes about 10 minutes to run on a GitHub free runner for about 250 total pages. That’s already not short (and for testing a static site)! Adding more screen widths scales linearly, which is not good. Some optimization is needed.
I haven’t yet done any work to optimize the pipeline, but some common tricks include:
- aggressive caching, which can help if changes are local to a file (e.g. a new post) — but changes that affect the layout of the entire site (e.g. changing the navbar) will invalidate the cache
- tweaking the Chrome/Selenium profile that we use (e.g. by disabling irrelevant browser features and adding a stricter request timeout)
- when possible, cutting down on external network requests (which are a huge part of our CI time when generating individual pages)
- potentially further re-engineering duplicated pages (e.g. each individual “tag” page is almost identical)
Separately, we’re also not evaluating accessibility changes after page interactions (e.g. toggling a button or running JavaScript). There aren’t many of these on the PLSE site (most content is just text!) but there are some, mostly centered around the calendar view under the various meeting pages.
To be super thorough, we may want to consider using different browsers and/or OSes. From my perspective, that’s not necessary yet: our site is static and doesn’t make use of CSS features or interaction paths that tend to be browser or OS-specific. If we can eventually cut down CI to be much faster, it’d be easy to spin up more runners with different profiles for each browser-OS pair.
Bigger Picture
Now that the quarter is over, I can re-focus and spend some time going through my open-source backlog. Among other things, I want to:
- resolve the last few issues with the core Just the Docs site and template
- work with Michael to make this a standalone test package that all JtD users (and perhaps, Jekyll or other SSG users) can “drop in” and use!
I’d also like to tackle some of the other next steps from the previous article, including copy-code buttons (light lift) and exploring accessible diagram visualizations (very heavy lift); among other things, I’m working with the awesome Ritesh Kanchi and Miya Natsuhara on an accessible diagramming tool that should extend well to PL & SE diagrams.
Closing Thoughts
This was a long post (both to read, and to write)! From my perspective, the key points aren’t really about Ruby, Jekyll, or Selenium — they’re just an application of computer science principles to accessibility. The bullet-point version of this blog post is:
- you can’t fix problems that you can’t find
- you should test early, test often, and test automatically
- with good tests, isolating and fixing problems is pretty simple
- picking the right level of abstraction for your data is important!
Not too bad! Everything else is just an “implementation detail” :)
Many thanks again to Michael Ball for his work in implementing the CI check used in this post; he deserves all the credit for putting these tools together in a way that even I could use them. And, many thanks to Alexandra Michael for her support in making this post come together (as well as her overall work as the steward of this blog) — this post literally would not exist without her work.
I’d love to hear from you if you have any thoughts! In the meantime, wishing you a restful end of the year :))