Tratto: Neuro-Symbolic Oracle Generation
Post Metadata
Crossing the Threshold
In 1931, Kurt Godel stunned the world of mathematics when he published his “Incompleteness Theorem.” To summarize, the theorem stated that, no matter what set of rules we believe to be true about our world, there will always be statements that are… unprovable. This infuriated various mathematicians, who had believed that mathematics would be the key to proving everything! Now, I am not a mathematician, and this blog post is not a discussion of logic. However, this research (which I promise we will discuss momentarily) is often plagued by a strong desire for absolute correctness and proof, much like the mathematicians of the past. This ailment is in direct opposition with the only true rule known about the world of software testing, which is: Software testing is very hard.
In an attempt to tie-in my verbose introduction, we may approach the subject of automated software testing – that is, the process of automatically generating a test suite for a given program – like an algorithm.
The first question being, “Why is software testing so hard?”
The answer lies neither with executing the generated tests nor generating test inputs.
The former being automated by JUnit and the latter being automated by tools such as EvoSuite and Randoop.
Instead, the difficulty arises in the sub-problem of “oracle generation”.
An oracle is a statement that should be true about a program in a given state.
In Java testing (which will be our primary focus), oracles manifest themselves as JUnit assertions.
For example, the oracle sum(a, b) == a + b indicates that the expected behavior of the method sum, when passed parameters a and b, is to return a + b.
In a test suite, this condition is wrapped in a JUnit assertion, such as assertTrue(sum(a, b) == a + b).
Why is oracle generation so difficult? As we know from Dijkstra, “Testing shows the absence, not the presence of bugs”. Recalling our analogy to mathematics, this is akin to the difference between a “there exists” proof and a “for all” proof. Ideally, we would like our tests to prove that our code works “for all” cases. However, a unit test only shows that “there exists” a case where our code works. “If we cannot prove that a method works for all cases, why don’t we generate several test inputs (using EvoSuite or Randoop), and use their method output to infer the expected behavior?” I hear you say. “Then, if this behavior changes between cases, we will know that we must have a bug!” These are known as “regression oracles”, and are used by various tools (EvoSuite has an option to generate regression oracles alongside its inputs). Although regression oracles have their uses, if the original implementation is faulty, then the oracles will simply reflect this faulty behavior.
How do we know what the behavior should be?
In Java testing, the expected behavior is described in the Javadoc (the Lovecraftian horror that is… undocumented code… is a separate issue, and outside the scope of this project).
However, this description is in natural language, which cannot be directly inserted as a JUnit assertion.
Instead, state-of-the-art tools, such as Jdoctor, derive oracles from formal specifications using a predefined set of rules and patterns.
When matched, these natural language snippets are directly translated into their Java equivalents.
For example, the Javadoc tag @param a must not be null may be translated as a != null.
These “symbolic” approaches perform well within their distribution of patterns, but fail to generalize to new distributions of text.
In contrast, purely “neural” approaches (which leverage a variety of techniques from deep learning) often generate many incorrect oracles, as the neural modules rarely guarantee compilability or correctness.
These shortcomings may sound bleak, but there is hope! In light of the current language modeling craze, we investigate how we may modify the greedy decoding strategies from language modeling to generate flexible, well-informed, and compilable oracles. To do so, we combine the aforementioned neural and symbolic approaches. Our tool is a transformed-based token-by-token oracle generator, that we call Tratto.
Approach the Inmost Cave
The next question is, “What do you mean by neuro-symbolic?” In the previous section, we discussed how the search for exact translations from Javadoc natural language to Java condition, is unable to generalize to new distributions of text. There are no sets of rules we can define to cover all possible Java method behaviors (a lesson all too familiar to the aforementioned mathematicians). Consequently, purely symbolic approaches are not sufficient for the task of oracle generation. In contrast, recent developments in natural language processing have shown that language models are capable of generalizing to wide distributions of text, due to their extensive pre-training. The primary concern for the average SDE is, “How do I know that what an LLM spits out will be correct?” This question is what birthed our “neuro-symbolic” approach. Our neural module is responsible for generating the oracle, but is moderated by an additional symbolic module, in order to provide some guarantees of correctness.
Symbolic Module
Our symbolic module has two main components: the grammar and the context retriever. These modules moderate the oracle generation process in two steps. First, we use retrieval-augmented generation (RAG) to append contextual information to our LLM prompt. Then, we are able to apply a filter to the list of token probabilities, to ensure that only syntactically valid tokens are decoded.
The grammar takes the current oracle being decoded, known as the “oracle under construction” (OUC), as input.
Then, the grammar references Java syntax to determine all next possible tokens for the OUC.
For example, consider the OUC this..
The grammar will retrieve a list of all accessible fields or methods from the receiver object (among any other possible tokens), but will not retrieve any tokens that would create an invalid expression (e.g. + is not retrieved, as this.+ is not a syntactically valid expression).
Using the list of possible tokens for the OUC, the context retriever searches the project under test for any Javadoc corresponding to possible tokens. This information is appended to our prompt for the neural module, in order to yield a more informed output.
Neural module
For our language model, we use CodeLLaMa-7B, a small LLaMa 2 model that has been fine-tuned on code and long-context tasks. We use a custom prompt for the task of oracle generation, and fine-tune the model on various method-oracle pairs. At each step, we only decode one token using our list of possible next tokens (hence the “token-by-token” part of Tratto). At inference time, the neural module only considers the list of syntactically valid tokens when decoding the next token.
Return with the Elixir
Now, possibly the most important question is, “Does it work?”
Results
To compare Tratto against the state-of-the-art approach, Jdoctor, we create a ground-truth dataset for axiomatic oracle generation. The dataset features 805 manually written oracles that we extracted from a set of 519 Java methods from 15 real-world projects in the Defects4J database. Two authors independently generated oracles for each Java method, with any conflicts resolved via open discussion.
We use both Tratto and Jdoctor to generate oracles for each method in the ground-truth dataset, and compare their output against our target oracles. For each oracle in the ground-truth dataset, there are four possible outputs from either tool:
- No oracle generated: the approach does not generate any oracle (N)
- Wrong oracle: the approach generates an oracle that does not align with the ground-truth oracle (W)
- Incomplete oracle: the approach generates an oracle that covers a strict subset of failures covered by the ground-truth oracle (I)
- Correct oracle: the approach generates an oracle that matches the ground-truth oracle (C)
Additionally, we report the precision and recall,
\[\begin{align*} Precision &= \frac{C}{W + I + C} \\ Recall &= \frac{C}{N + W + I + C} \end{align*}\]Precision may be informally interpreted as, “Of the oracles generated by an approach, what percentage are correct?” Recall may be informally interpreted as, “Of all possible oracles in the ground-truth dataset, what percentage are correctly generated by an approach?” We provide these results in the following table:
| Tool | N | W | I | C | Precision | Recall |
|---|---|---|---|---|---|---|
| Jdoctor | 654 | 2 | 13 | 54 | 78 | 7 |
| Tratto | 551 | 31 | 8 | 214 | 86 | 27 |
Our results show that Tratto is able to outperform Jdoctor in terms of both precision and recall. This suggests that Tratto is not only more correct than Jdoctor, but also provides better coverage.
We provide a few informative examples from the ground-truth dataset to illustrate why Tratto is able to outperform Jdoctor. First, we consider the correctness (precision) of oracles generated by Jdoctor. Consider the following example from the JsonArray class in the Gson project:

For this example, Jdoctor generates the exceptional oracle, this.isEmpty(), which does not align with the target oracle, this.isEmpty() || this.size() > 1.
Jdoctor’s symbolic approach was designed to match predetermined patterns, in order to avoid generating incorrect oracles.
However, this example illustrates a case where Jdoctor matches a pattern, but was unable to capture all necessary information.
In contrast, Tratto is able to successfully generate the correct oracle, as its neural approach provides more flexibility outside rigid patterns.
Additionally, we consider the coverage (recall) of both Jdoctor and Tratto. Consider the following two examples, from the Decoder class in the Codec project and the Base64 class in the Codec project, respectively:
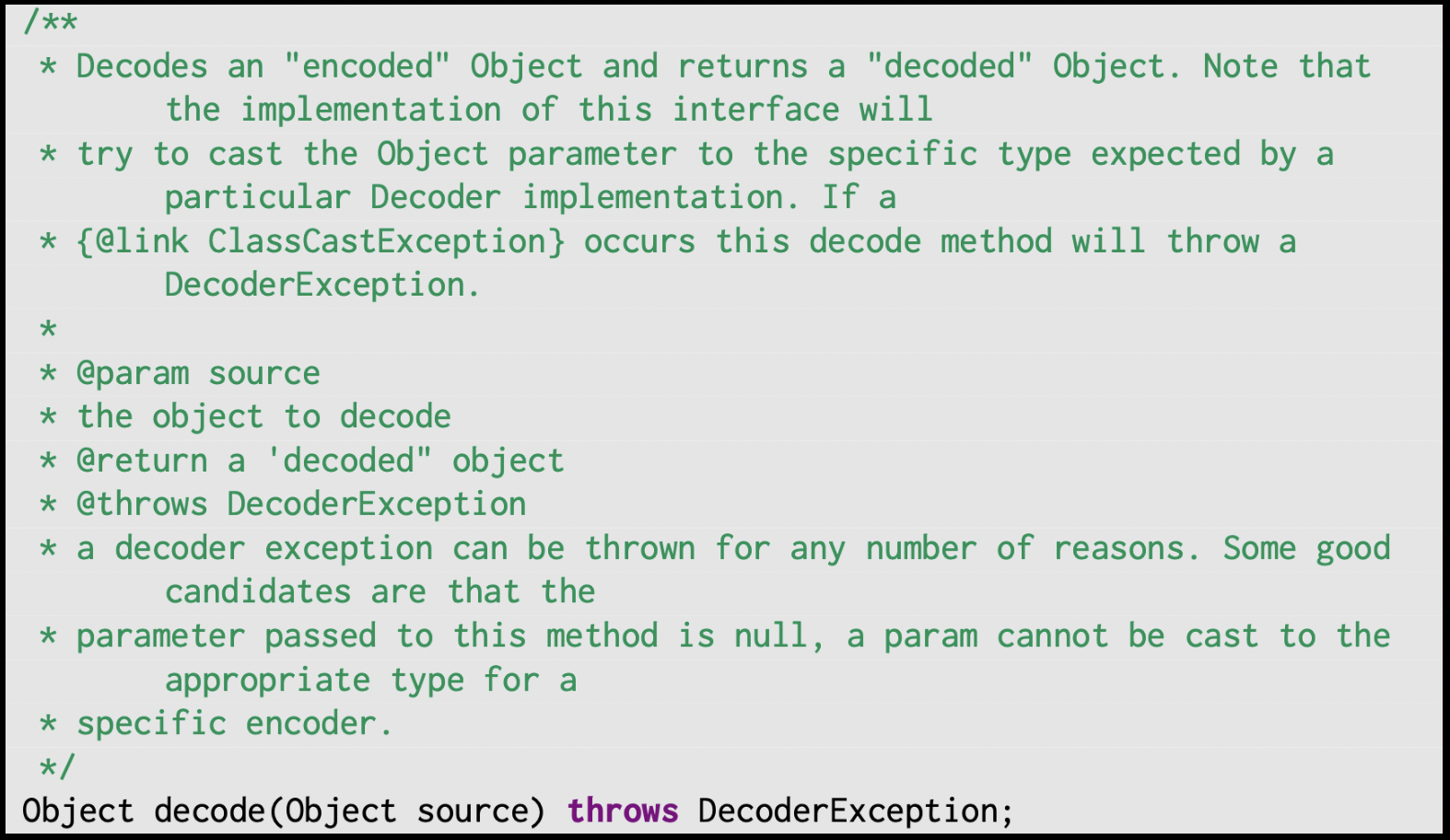
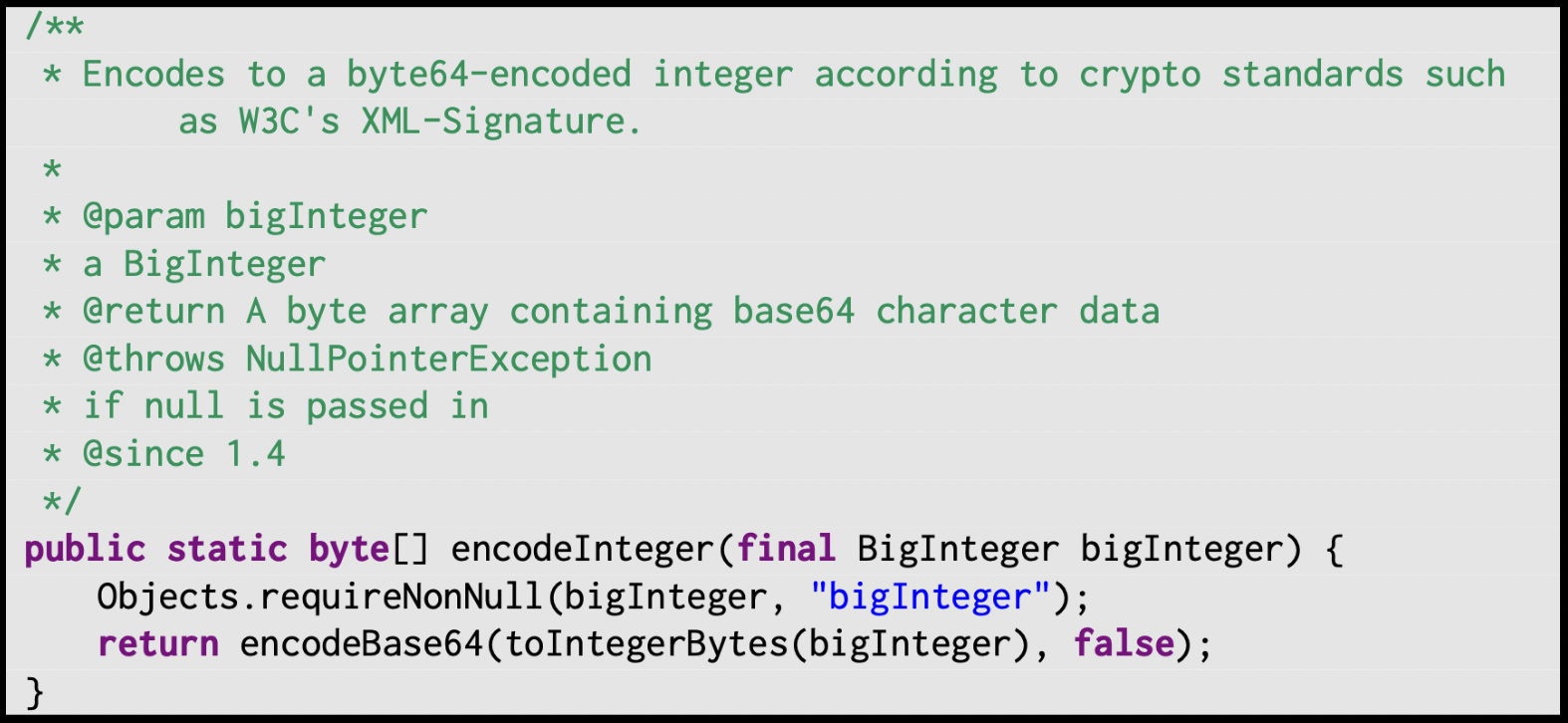
These methods have very similar exceptional oracles, source == null and bigInteger == null, respectively.
Although Jdoctor is able to generate the exceptional oracle source == null, it is not able to generate the exceptional oracle bigInteger == null.
This is another symptom of the aforementioned problem, Jdoctor’s inability to generalize beyond its predetermined templates.
As previously mentioned, this issue is common among any symbolic approaches, as any set of rules is unable to cover all distributions of Java code.
In contrast, Tratto’s neural approach is able to generalize beyond rigid templates.
This robustness is further bolstered by our data augmentation, which helps Tratto understand the same oracle in different contexts.
Discussion
Automatically generating axiomatic oracles is still a largely open problem. Tratto modifies the typical language model decoding strategy by applying a symbolic module before decoding each subsequent token. In doing so, Tratto is able to balance the comprehensiveness and compilability of symbolic tools with the generalizability of neural tools. Tratto is able to infer roughly four times more oracles than the state-of-the-art symbolic approach, Jdoctor, with a relatively small and comparable number of incorrect or incomplete oracles.
Ultimately, Tratto still has several limitations. Most significantly, despite our manual contributions, a majority of Tratto’s training data is derived from Jdoctor’s output. Consequently, most oracles derived by Tratto are similar to the patterns defined in Jdoctor. For future work to improve the recall of neural oracle generation tools, the core neural models should be trained using larger datasets that span a greater diversity of axiomatic oracles. Similarly, future work could use larger models, such as CodeLLaMa-70B, to investigate potential performance improvements due to scaling.