The Science of Code Formatting (Part I)
Code formatters are tools to make source code in a programming language easy to read. This series of blog posts presents a systematic analysis of code formatters. We aim to answer the following questions: What are the advantages and disadvantages of different kinds of code formatters (for both users and implementers)? How do they work? And what are some open problems in this space?
(Automatic) code formatting has become very popular in the past decade. Many modern programming languages even include a code formatter along with its main implementation, showing how integral the tool has become in code development. This post will be an introduction to the topic of code formatting. We will start by reviewing its use-cases, and then analyze features of code formatters based on various classifications.
Applications of Code Formatting
An obvious use-case of code formatters is to reformat poorly formatted code, so that the formatted code conforms to coding conventions or style guides. This makes the code easy to read and maintain.
|
|
An important aspect of readability is consistency #. Especially in collaborative projects, collaborators should use the same coding convention consistently. Code formatters are thus often employed to enforce consistent conventions.
One indirect benefit is an improved code reviewing process. Pull requests with inconsistent formatting are likely to result in change requests to fix the issues. This blocks the merge, wasting the time of both the submitter and reviewer. With a code formatter, the submitter can catch these mistakes before the review process begins (e.g. by running the code formatter locally, or as a part of the CI).
Code formatters can also be seen as convenience tools to automate tedious formatting tasks. For example, in the Go language, it is preferable that types and variables are aligned in a “tabular layout”, which looks nice to readers. However, manually formatting this tabular layout is tedious, as it potentially involves editing many lines to align the code. What a Go user would do is to write their program without taking the tabular layout into consideration, and then rely on the Go code formatter to format the tabular layout properly.
|
|
string, int, and string are aligned to be on the same column position.
Another application is to use the tools in code generation or program synthesis. Traditionally, code generation produces a syntax tree that lacks source location. As a result, a naive output from code generation usually puts everything in a single line, which is difficult to read. Code formatters can be employed to make the output human-readable.
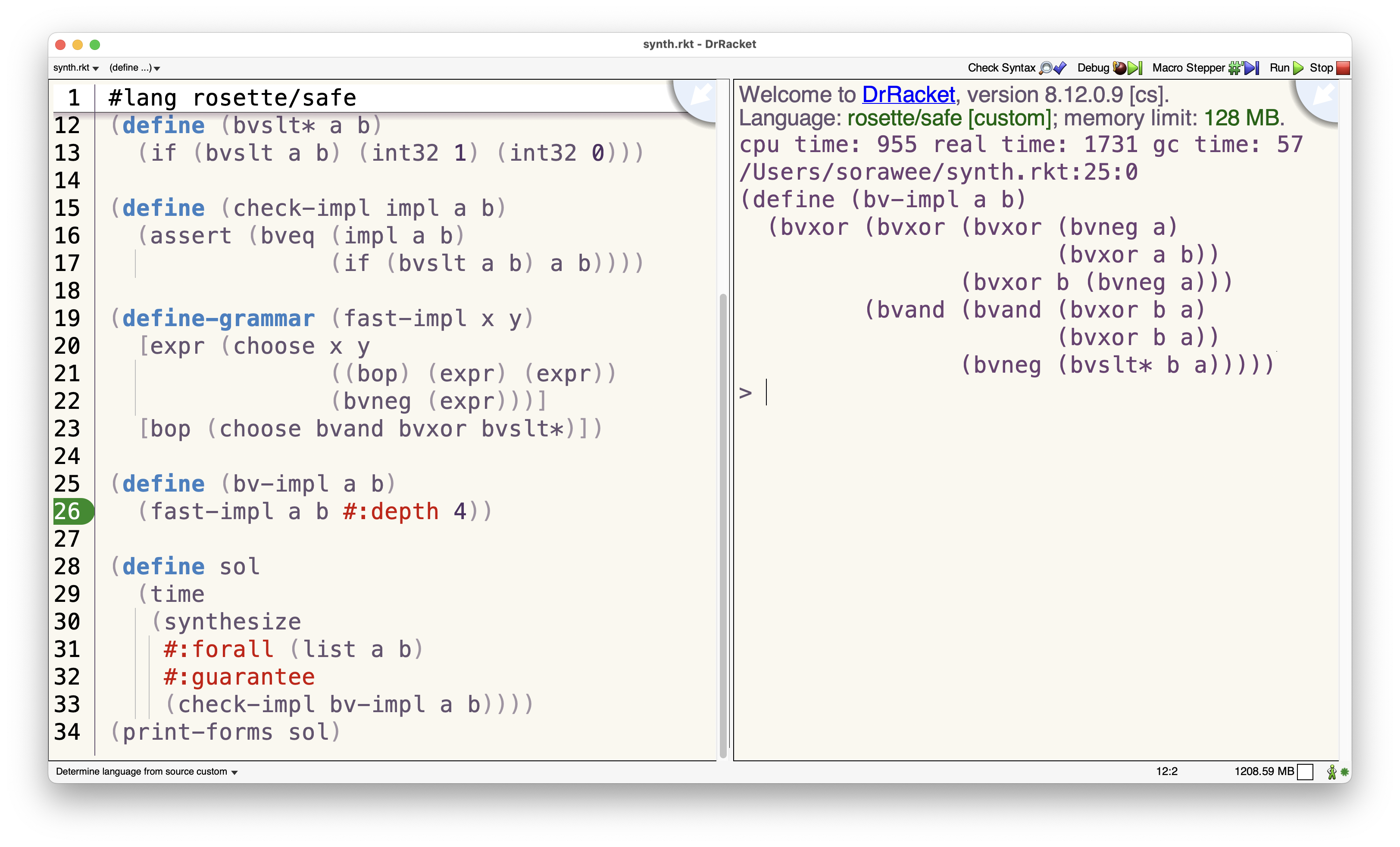
int32 variables a and b.
The synthesized code is formatted with a code formatter so that it is readable.
One can also use code formatters in computing education: the formatters can not only help making students’ code more readable, but also give them examples of how to properly format their code.
I hope you are convinced now why code formatters are valuable. As it turns out, there are actually many kinds of code formatters. In the next section, we will take a look at different types of code formatters and see what their advantages and disadvantages are.
Classifications of Code Formatters
Most code formatters follow the same pipeline. They first read the source code into a representation that can be easily analyzed. They then perform formatting on the representation, producing a formatted code. Details of these steps can vary significantly in different code formatters, however.
An important classification of code formatters is whether the formatting process honors the page width limit, which is the number of characters that line lengths should not exceed. The page width limit is a very common element in coding style guide. Intuitively, an overly long line is bad: the line might be soft-wrapped by an editor, which is difficult to read. The editor might alternatively be configured to only show the code partially, requiring users to use a horizontal scroll bar to view the other parts, which is also not ideal. The page width limit is thus a threshold to prevent this problem. We call code formatters line-preserving if they do not honor the page width limit, or line-breaking otherwise.
Line-Preserving vs Line-Breaking
A line-preserving code formatter does not honor the page width limit. It mostly formats whitespaces within each line, but preserves line breaks in the original code. That is, it will not add line breaks to split up a long line that goes over the page width limit, or consolidate short lines that could fit under the page width limit.
func quicksort(xs []int) []int {
if len(xs) <= 1 {
return xs
} else {
pivot := xs[0]
var less_than, greater_than, same []int
for _, x := range xs {
if x == pivot {
same = append(same, x)
} else if x < pivot {
less_than = append(less_than, x)
} else {
greater_than = append(greater_than, x)
}
}
return append(append(quicksort(less_than), same...), quicksort(greater_than)...)
}
}quicksort function in Go,
via gofmt, which is mostly a line-preserving code formatter.
Because the formatter will not add a line break,
the formatted code could exceed the page width limit,
illustrated with the red verticle line.
The family of line-preserving code formatters is exemplified by the Go code formatter gofmt†,
which popularizes code formatting in modern languages.
Tools like code indenter, commonly implemented for Emacs modes,
could also be seen as a form of line-preserving code formatter.
There are advantages of line-preserving code formatters, however.
Users know the semantics of their program,
and could deliberately use line breaks to make the meaning of the program clear.
In Fig 6,
the function place_image consumes an image,
two numbers that together specify a coordinate for image placement,
and then a background image.
The users could intentionally place the two numbers together,
separated from other arguments,
to highlight the fact that they form a coordinate.
This fact would not be apparent to code formatters.
But because line-preserving code formatters preserve the existing line breaks,
the formatting decisions by the users are still respected.
To put it differently, line-preserving code formatters do not make any formatting decisions on their own.
For this reason, line-preserving code formatters are also known as unopinionated.
In contrast, the formatters that honor line breaks will usually make
their own formatting decisions from scratch,
disregarding decisions by the users,
as shown in Fig 7.
return place_image(
segment_right,
350, 200,
place_image(
segment_up,
285, 300,
place_image(
segment_down,
200, 200,
place_image(
segment_up,
115, 110,
place_image(
segment_right,
50, 200,
empty_scene(400, 400, plse_color),
),
),
),
),
)place_image,
I put the second and third arguments together to make it clear that they form a coordinate,
and the code formatter preserves this formatting decisions.
The line-preserving code formatters are also relatively simpler, and easier to implement, compared to formatters that honors the page width limit. And as a result, they tend to have great performance.
Because of these characteristics, line-preserving code formatters are suitable as convenience tools for formatting, but may have relatively limited value for making formatted code consistent.
On the other hand, a line-breaking code formatter will honor
the page width limit.
That is, it will try to add line breaks to split up a long line that
goes over the page width limit,
and consolidate short lines that could fit under the page width limit.
This is the original form of code formatting,
which appeared in the code formatters for ALGOL 60 and LISP [1, 2].
Modern line-breaking code formatters include:
Prettier for JavaScript,
clang-format for C (when ColumnLimit is not 0),
and rustfmt for Rust.
Because formatting decisions are (mostly) made without considering
the formatting in the original code,
line-breaking code formatters are also known as opinionated § [3].
This ensures consistency, at the cost of losing
the original formatting decisions made by the users.
return place_image(
segment_right,
350,
200,
place_image(
segment_up,
285,
300,
place_image(
segment_down,
200,
200,
place_image(
segment_up,
115,
110,
place_image(
segment_right,
50,
200,
empty_scene(400, 400, plse_color),
),
),
),
),
);Making a line-breaking code formatter is much more challenging than making a line-preserving code formatter, as there can be many formatting choices (usually exponentially many) to make decisions over. This means performance can become an issue in line-breaking code formatters if their algorithm is inefficient.
At the heart of line-breaking code formatting is pretty printing, which is a process that makes formatting decisions when converting the representation of the source code into formatted text. The line-breaking formatters can in fact be further subdivided according to their underlying pretty printer, the engine that does pretty printing. We will leave the topic of pretty printing as the subject for the next blog posts.
Other Classifications
Although the main classification of code formatters is about the treatment of the page width limit, code formatters can also be classified with various other criteria.
Token representation vs syntax tree representation:
Some code formatters read the source program by lexing it into a list of tokens.
Other code formatters read the source program by further parsing the tokens into a syntax tree.
The token representation lacks structure,
and works well only for some target languages whose formatting rules are simple enough that they can be determined based on tokens.
scalafmt [3] for the Scala language is an example of a code formatter with the token representation.
The tree representation by constrast is structured,
but it is more difficult to construct.
One primary problem with the tree representation is comment handling,
as traditionally comments are discarded before parsing.
The syntax tree must be designed to preserve comments somehow,
which is possible, but non-trivial.
rfmt [4] for the R language is an example of a code formatter with the tree representation.
Lenient reading vs strict reading:
The reading step in code formatters maybe lenient.
Even when there's a syntax error in the source code,
the code formatter will still try to read the code to the best of its ability.
In constrast, strict reading simply fails when encountering a syntax error.
Being lenient is obviously desirable, but that comes at the cost of complexity in the reader.
Furthermore, it may not be possible to create a lenient reader for e.g. languages whose reading is specified within the program
(such as Racket).
Leniency is in fact a spectrum and not binary.
For instance, a code formatter with the token representation might be neither lenient nor strict: it might require that lexing is successful, but not parsing.
clang-format is an example of a code formatter with lenient reading,
while Prettier is an example of a code formatter with strict reading.
|
|
clang-format,
which can handle the errors.
Fixed formatting vs extensible formatting: In a code formatter, the formatting rules may be fixed, which do not allow users to add more rules. By contrast, extensible formatting rules allow users to add more rules. Extensibility is especially relevant for languages with macros or user-defined syntactic abstractions, as users may want their macro invocations to be formatted in a way that they desire. While there are many line-preserving code formatters that are extensible (e.g., Elisp's macro indentation customization), the customization tends to be very limiting. Line-breaking code formatters further experience extra challenges to make them extensible, as they must allow users to specify arbitrary formatting choices that the users wish, so that the code formatters can make formatting decisions on these choices. To the best of my knowledge, my Racket code formatter is the only line-breaking code formatter that is fully extensible. This is accomplished by using our novel pretty printer [5] that is composable and expressive (the topic of the next blog posts).
Refactoring vs non-refactoring: Some code formatters may convert one construct to another that is more preferable in the style guide. Some may sort the import statements. Arguably, these are an extreme form of opinionated changes‡ that warrant a new category: refactoring code formatting. The resulting code from a refactoring code formatter would be even more consistent than the non-refactoring ones. One downside is that users may expect code formatting to be simple and easy to verify that it is correct, but this refactoring can introduce the complexity that users may not expect. Other non-refactoring code formatters usually only involve whitespace changes. However, it would be wrong to restrict non-refactoring code formatting to only whitespace changes. Fig 9 shows two formatting choices that a non-refactoring Python code formatter might consider. The vertical style has an extra pair of parentheses, due to the requirement in Python’s grammar.
|
|
Incremental vs non-incremental: During code development, users might call a code formatter several times. An incremental code formatter uses previous formatting to speed up formatting. This can be done in several ways. For example, the code formatter might save the previous formatted output, and only perform formatting in the regions where there are changes. Or if the formatting algorithm uses dynamic programming, the code formatter might reuse the dynamic programming table, so that previously computed subproblems do not need to be recomputed again. The popularly used language server could also help by maintaining states from the previous formatting. This incremental formatting must be done with care, however, as it should still be behaviorally equivalent to the full formatting from scratch. A non-incremental code formatter, by contrast, does not use previous formatting. This makes the code formatter simpler. Especially if the code formatter is already fast, it might not make much sense to support the complex incremental feature.
Outro
In this blog post, we went over how code formatting is useful, and then looked at trade-offs of different features in code formatters. The next post in the series will talk about desirable properties of code formatters, and then focus on line-breaking code formatters (particularly the pretty printing process), as they are more widely used. Moreover, they are interesting algorithmically and have a beautiful PL theory behind them.
Thanks to Gus Smith and Justin Pombrio for edit suggestions.
[1] R. S. Scowen et al. SOAP - A Program which Documents and Edits ALGOL 60 Programs. Comput. J. 14(2): 133-135 (1971).
[2] Ira Goldstein. Pretty-printing Converting List to Linear Structure. Massachusetts Institute of Technology. Artificial Intelligence Laboratory, 1973.
[3] Ólafur Páll Geirsson. scalafmt: opinionated code formatter for Scala. 2016.
[4] Phillip Yelland. A New Approach to Optimal Code Formatting. 2016.
[5] Sorawee Porncharoenwase, Justin Pombrio, and Emina Torlak. A Pretty Expressive Printer. Proc. ACM Program. Lang. 7(OOPSLA2): 1122-1149 (2023).
#: There are different scales of consistency. This post focuses on consistency within a project, but some people may only care about consistency within a file. Others may prefer that the language provides one true way to format code that everyone must follow.
§: The definition of “opinionated” in this post follows the master’s thesis by Ólafur Páll Geirsson [3]. However, some people may colloquially use “opinionated” to mean being less flexible or having few configuration options. The goal in the end for opinionated code formatters is to improve consistency, and it could be argued that having many knobs for users to adjust decreases the level of consistency.
†: Go is mostly a line-preserving code formatter, but it does have heuristics to add line breaks in some cases (including to avoid going over the page width limit in some of these cases), as shown below.
|
|
gofmt.
‡:
It may be somewhat surprising that gofmt, which is an unopinionated code formatter, is refactoring.
For example, with the right settings, it would simplify arr[start:len(arr)] to arr[start:].
code-formatting
pretty-printing